

The short version
VALL-E was Microsoft’s 2023 text-to-speech research model for synthesizing new speech in a target voice from a three-second recording. It encoded text and audio into discrete values, predicted audio codec tokens with a language-model-like architecture, then decoded them into speech that could preserve speaker and acoustic cues. The post also notes how easily voice, generated text, and deepfakes could be combined, so read it as a launch-era result.
Last year we saw the uprising of generative AI for both images and text, most recently with ChatGPT. Now, within the first week of 2023, researchers have already created a new system for audio data called VALL-E.
VALL-E is able to imitate someone’s voice with only a 3-second recording with higher similarity and speech naturalness than ever before. ChatGPT is able to imitate a human writer; VALL-E does the same for voice.
Let’s see how they were able to clone someone’s voice and hear some results (or hear them on Microsoft Research’s VALL-E project page):
Also, I am once again partnering with the World’s AI Cannes Festival and running a cool giveaway as well as discounts for you if you’d like to attend the event happening this February. I was there in person last year and had a great time. Highly recommend attending, especially if you are in Europe or near Cannes. More details at the end of the article!
As you’ve heard, the results are incredible. You can now easily generate text using ChatGPT and then give it a human voice using VALL-E. Merge that with a deepfake and you have a completely fake human being to produce infinite content automatically! Things are just getting crazier with time, but what’s even cooler than those advancements is how they are made…
So how can we imitate someone’s voice?
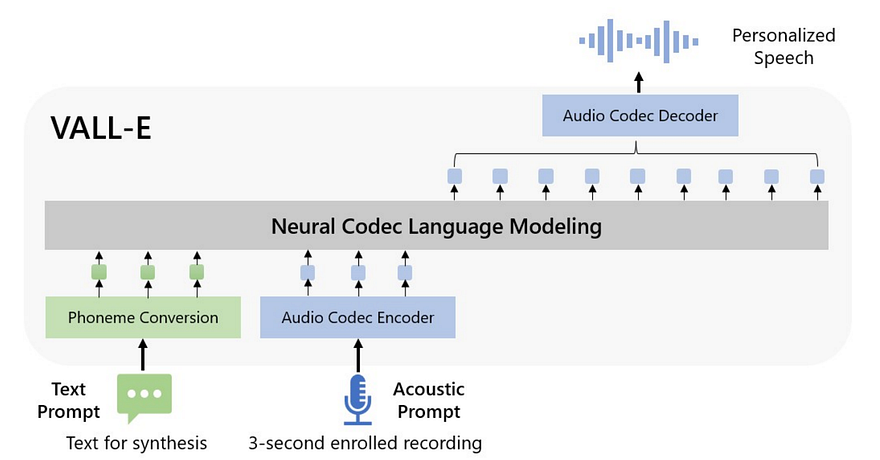
The overview of VALL-E. Image from the paper.
We start by encoding a short example of a text message you want to generate along with the voice you plan to imitate, which we call our prompts. These prompts will be sent to another model, which will generate our audio codec codes and then decode these into a new personalized speech.
As I mentioned, we first have our text and audio prompts that contain the text for the speech generation along with the voice we want to imitate. Then, we want to give them to our main model for it to generate our new audio. For that, we need to translate it into something our model can understand, which is often matrices and numbers, not words or sounds. This means we will use other models called encoders to go from text and voice to matrices and specific values and numbers representing the speaker and acoustic information. This is the same step as with most language models to understand and treat language inputs.
Then, we need to take these newly created matrices representing the voice and the text we want and do some magic to merge the two creating a new audio track with the cloned voice and desired text.
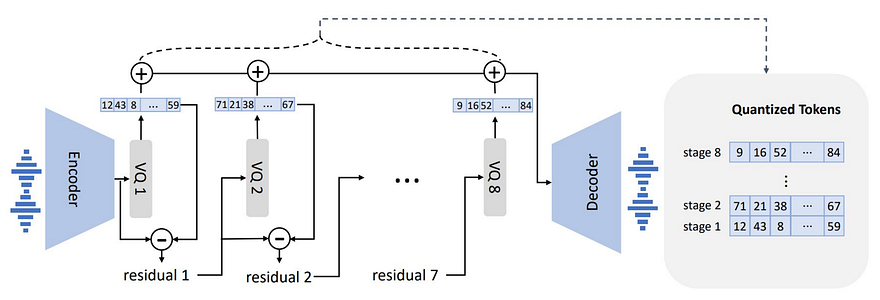
The overview of the neural codec language model. Image from the paper.
This is where our main model comes in, our neural audio codec model. It will take the matrices we just produced and learn to best clone the voice while matching the new text. This works using a relatively basic model architecture called a convolutional encoder-decoder, as we’ve seen in GANs and other approaches in many of my previous videos for generating images. This encoder-decoder network will simply learn from its examples during training to clone the voice by compressing the information keeping only the most relevant content and using this compressed version of what we have to reconstruct the new audio we want. It will work, thanks to the thousands of examples it has seen during its training phase, just like how a professional tennis player already knows where the ball will land on his side of the court as soon as the other player hits the ball. Because of what he has seen in the past, he’s able to predict where the ball will end up and how it will bounce, only taking the initial hit into account.
Now that we have our transformed matrices, the only step is to take it back to the real world, which means creating an audio track from it. This is done using a very similar architecture as the audio encoder we’ve seen in the first step but in reverse. It was actually trained together to go from audio, encode it in matrices and numbers and get it back to the same audio. Then, we can split this model in two and use the first half in the first step we’ve seen and the second half right here to get our final results: our new personalized speech.

A comparison between VALL-E and current cascaded TTS systems. Image from the paper.
And why does it work so well? Because of this architecture we just described tackling this task as a language model task with audio codec codes instead of the traditional mel spectrogram approach, but mainly because they leveraged a huge amount of semi-supervised data, more specifically hundreds of times larger than existing systems, similar to recent large models like GPT-3 or ChatGPT. As always, data is the key.
And voilà! This is how you can copy someone’s voice and say anything you want, which is both fascinating and incredibly dangerous.
I’d love to hear your thoughts on all those new generative tools like this VALL-E model and ChatGPT. Did you expect such fast progress? What do you think is the next step regarding generative content?
Now is the time for our giveaway! The World’s AI Cannes Festival sent me five tickets to give to my community along with a 20% discount for everyone using the first link in my description. But why should you attend? Well, for multiple reasons. Personally, I really liked chatting with all the different startups there and meeting many incredibly talented people. But there are other cool perks, like amazing talks from professionals such as Yann Lecun or Lila Ibrahim from Deepmind. This is a great event to learn and network with European AI companies, and now is your chance to have a free ticket if you want to go to this beautiful city this February.
There are only two steps to enter the giveaway, join our Discord community called Learn AI Together, where we host and share all our favorite AI events, and write me a message on discord (Louis B#1408) with what you look forward to for this event and your Discord username for me to reach out.
I wish you the best of luck with the giveaway and hope you’ve enjoyed this article. I will see you next time with another amazing paper!
References
- Link for the audio samples: Microsoft Research VALL-E project
- Wang et al., 2023: VALL-E. https://arxiv.org/pdf/2301.02111.pdf
FAQ
What is Microsoft's VALL-E?
VALL-E is a text-to-speech model that can synthesize speech in a target voice from a short audio prompt.
How does the model represent speech?
An audio codec converts sound into discrete numerical tokens that a language-model-like system can predict.
What does the voice prompt provide?
It supplies speaker identity and acoustic characteristics that condition how the new text should sound.
Can VALL-E preserve the recording environment?
The demonstrated model can reflect aspects of the prompt's acoustic environment as well as the speaker.
What risks come with voice cloning?
Impersonation, fraud, non-consensual use, and false recordings require access controls, disclosure, and provenance.