Barbershop: Try Different Hairstyles and Hair Colors from Pictures (GANs)
This AI can transfer your hair to see how it would look like before committing to the change.


Watch the video and support me on YouTube!
This article is not about a new technology in itself. Instead, it is about a new and exciting application of GANs. Indeed, you saw the title, and it wasn't clickbait. This AI can transfer your hair to see how it would look like before committing to the change. We all know that it may be hard to change your hairstyle even if you'd like to. Well, at least for myself, I'm used to the same haircut for years, telling my hairdresser "same as last time" every 3 or 4 months even if I'd like a change. I just can't commit, afraid it would look weird and unusual. Of course, this all in our head as we are the only ones caring about our haircut, but this tool could be a real game-changer for some of us, helping us to decide whether or not to commit to such a change having great insights on how it will look on us. Nonetheless, these moments where you can see in the future before taking a guess are rare. Even if it's not totally accurate, it's still pretty cool to have such an excellent approximation of how something like a new haircut could look like, relieving us of some of the stress of trying something new while keeping the exciting part. Of course, haircuts are very superficial compared to more useful applications. Still, it is a step forward towards "seeing in the future" using AI, which is pretty cool. Indeed, this new technique sort of enables us to predict the future, even if it's just the future of our haircut. But before diving into how it works, I am curious to know what you think about this. In any other field:
What other application(s) would you like to see using AI to "see into the future"?

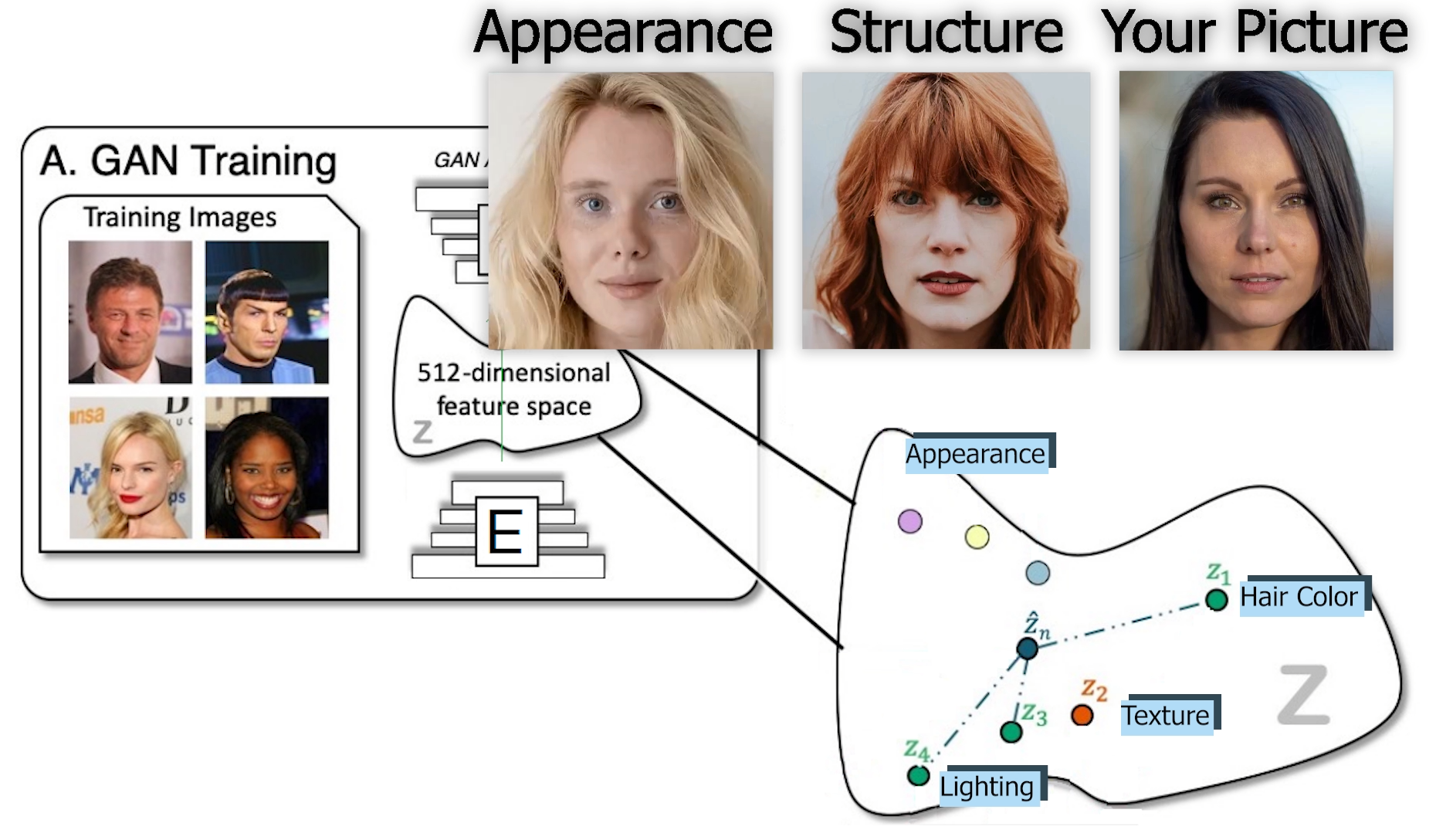
It can change not only the style of your hair but also the color from multiple image examples. You can basically give three things to the algorithm:
- a picture of yourself
- a picture of someone with the hairstyle you would like to have and
- another picture (or the same one) of the hair color you would like to try
and it merges everything on yourself realistically.
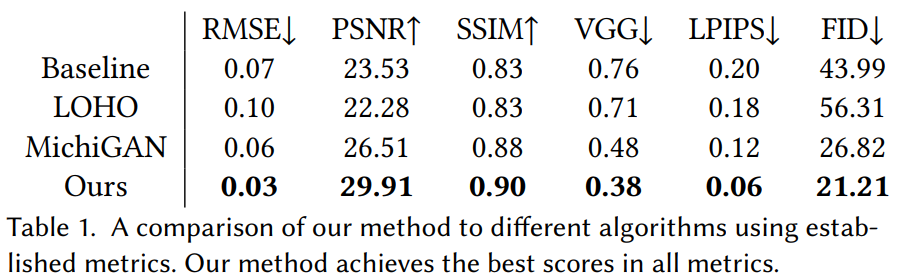
The results are seriously impressive. If you do not trust my judgment, as I would completely understand based on my artistic skill level, they also conducted a user study on 396 participants. Their solution was preferred 95 percent of the time! Of course, you can find more details about this study in the references below if this seems too hard to believe.
As you may suspect, we are playing with faces here, so it is using a very similar process as the past papers I covered, changing the face into cartoons or other styles that are all using GANs. Since it is extremely similar, I'll let you watch my other videos where I explained how GANs work in-depth, and I'll focus on what is new with this method here and why it works so well.
A GAN architecture can learn to transpose specific features or styles of an image onto another. The problem is that they often look unrealistic because of the lighting differences, occlusions it may have, or even simply the position of the head that are different in both pictures. All of these small details make this problem very challenging, causing artifacts in the generated image. Here's a simple example to better visualize this problem, if you take the hair of someone from a picture taken in a dark room and try to put it on yourself outside in daylight, even if it is transposed perfectly on your head, it will still look weird. Typically, these other techniques using GANs try to encode the pictures' information and explicitly identify the region associated with the hair attributes in this encoding to switch them. It works well when the two pictures are taken in similar conditions, but it won't look real most of the time for the reasons I just mentioned. Then, they had to use another network to fix the relighting, holes, and other weird artifacts caused by the merging. So the goal here was to transpose the hairstyle and color of a specific picture onto your own picture while changing the results to follow the lighting and property of your picture to make it convincing and realistic all at once, reducing the steps and sources of errors.
If this last paragraph was unclear, I strongly recommend watching the video at the end of this article as there are more visual examples to help to understand.
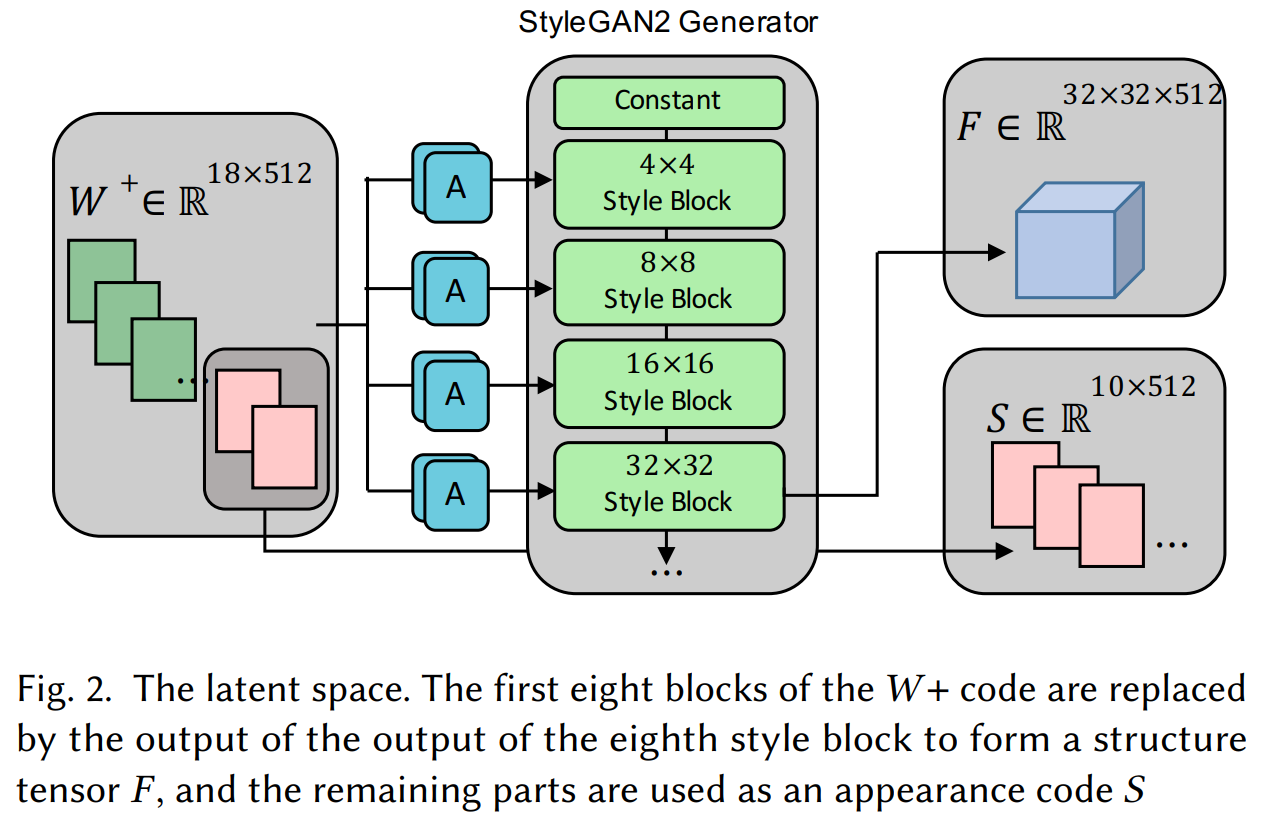
To achieve that, Peihao Zhu et al. added a missing but essential alignment step to GANs. Indeed, instead of simply encoding the images and merge them, it slightly alters the encoding following a different segmentation mask to make the latent code from the two images more similar. As I mentioned, they can both edit the structure and the style or appearance of the hair.
Here, the structure is, of course, the geometry of the hair, telling us if it's curly, wavy, or straight. If you've seen my other videos, you already know that GANs encode the information using convolutions. This means it uses kernels to downscale the information at each layer and makes it smaller and smaller, thus iteratively removing spatial details while giving more and more value to general information to the resulting output. This structural information is obtained, as always, from the early layers of the GAN, so before the encoding becomes too general and, well, too encoded to represent spatial features.
Appearance refers to the deeply encoded information, including hair color, texture, and lighting. You know where the information is taken from the different images, but now, how do they merge this information and make it look more realistic than previous approaches?
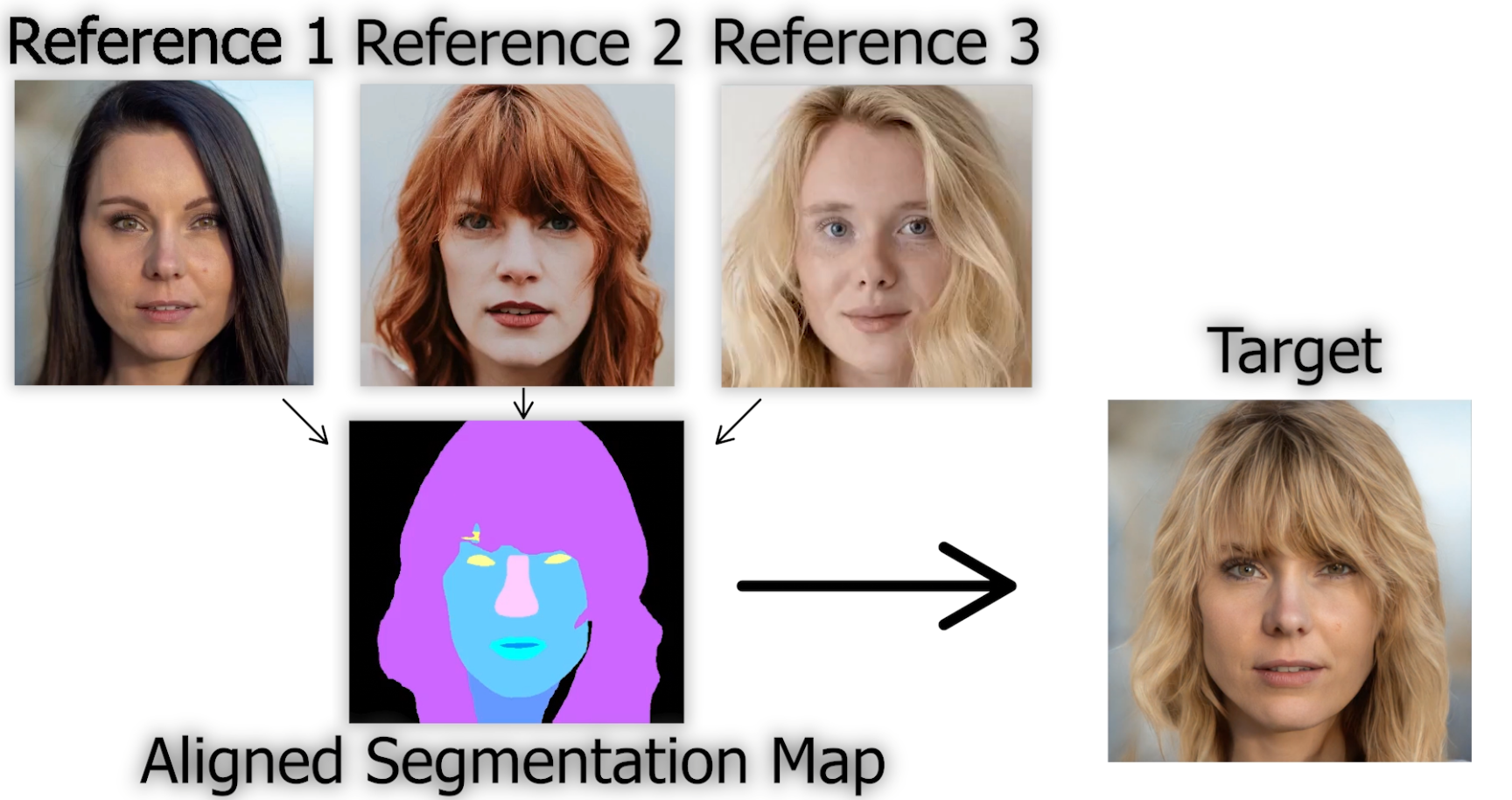
This is done using segmentation maps from the images. And more precisely, generating this wanted new image based on an aligned version of our target and reference image. The reference image is our own image, and the target image the hairstyle we want to apply. These segmentation maps tell us what the image contains and where it is, hair, skin, eyes, nose, etc.
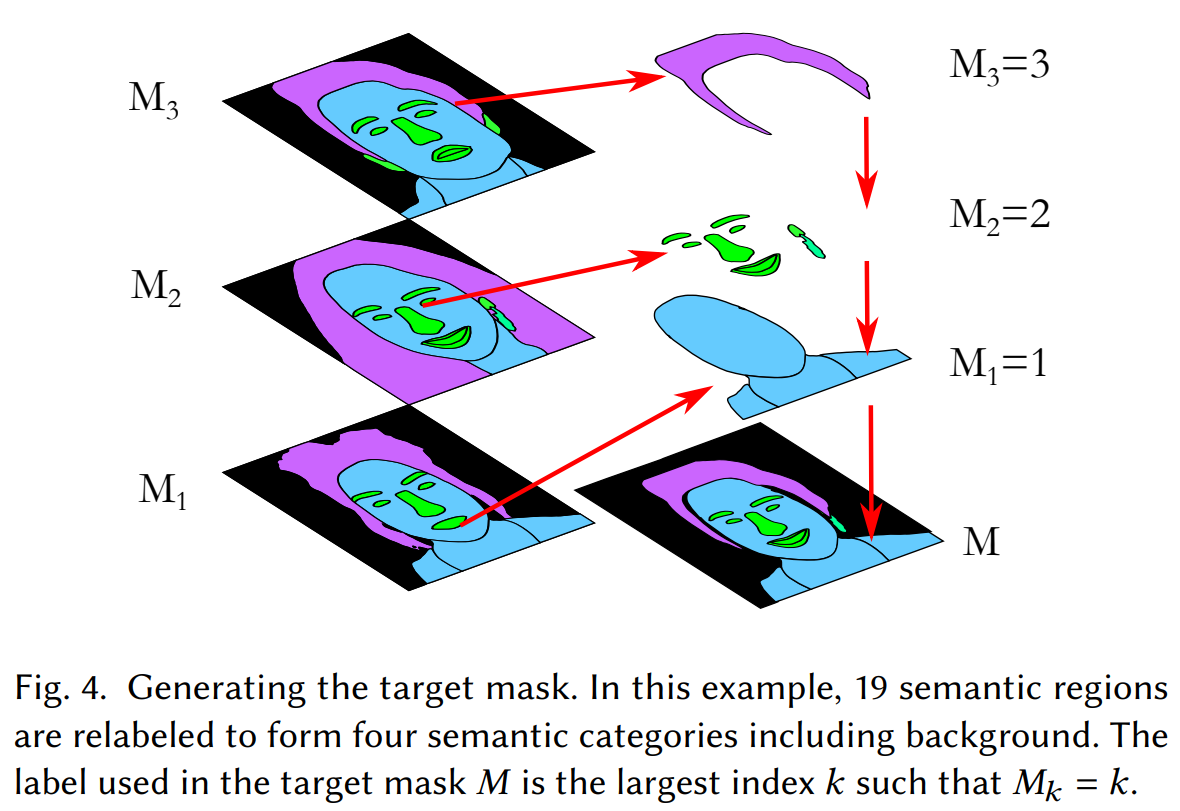
Using this information from the different images, they can align the heads following the target image structure before sending the images to the network for encoding using a modified StyleGAN2-based architecture. One that I already covered numerous times. This alignment makes the encoded information much more easily comparable and reconstructable.

Then, for the appearance and illumination problem, they find an appropriate mixture ratio of these appearances encodings from the target and reference images for the same segmented regions making it look as real as possible. Here's what the results look like without the alignment on the left column and their approach on the right.

Of course, this process is a bit more complicated, and all the details can be found in the paper linked in the references. Note that just like most GANs implementations, their architecture needed to be trained. Here, they used a StyleGAN2-base network trained on the FFHQ dataset. Then, since they made many modifications, as we just discussed, they trained a second time their modified StleGAN2 network using 198 pairs of images as hairstyle transfer examples to optimize the model's decision for both the appearance mixture ratio and the structural encodings.
Also, as you may expect, there are still some imperfections like these ones where their approach fails to align the segmentation masks or to reconstruct the face. Still, the results are extremely impressive and it is great that they are openly sharing the limitations.

As they state in the paper, the source code for their method will be made public after an eventual publication of the paper. The link to the official GitHub repo is in the references below, hoping that it will be released soon.
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
- Peihao Zhu et al., (2021), Barbershop, https://arxiv.org/pdf/2106.01505.pdf
- Project link: https://zpdesu.github.io/Barbershop/
- Code: https://github.com/ZPdesu/Barbershop