Deepmind's new model Gato is amazing!
Gato: A single Transformer to RuLe them all! The first generalist RL agent using transformers!


Watch the video!
Gato from DeepMind was just published! It is a single transformer that can play Atari games, caption images, chat with people, control a real robotic arm, and more! Indeed, it is trained once and uses the same weights to achieve all those tasks. And as per Deepmind, this is not only a transformer but also an agent. This is what happens when you mix Transformers with progress on multi-task reinforcement learning agents.
As we said, Gato is a multi-modal agent. Meaning that it can create captions for images or answer questions as a chatbot. You’d say that GPT-3 can already do that, but Gato can do more… The multi-modality comes from the fact that Gato can also play Atari games at the human level or even do real-world tasks like controlling robotic arms to move objects precisely. It understands words, images, and even physics.
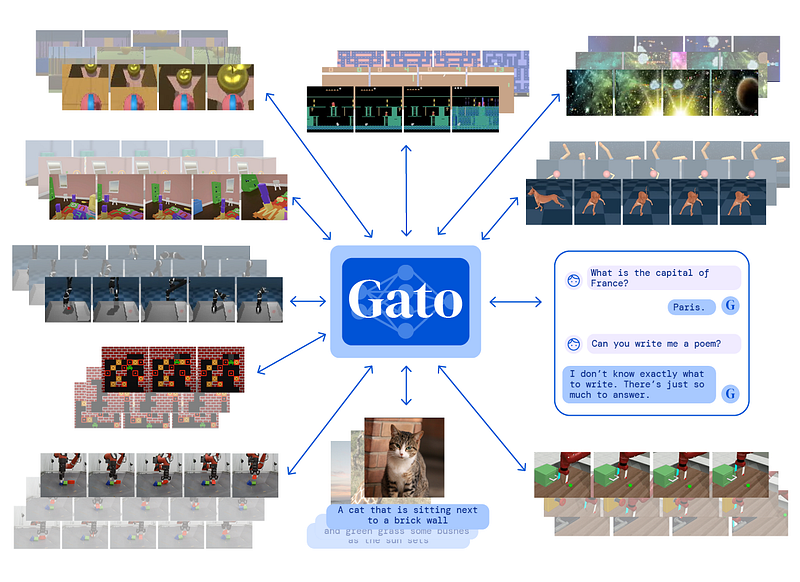
Gato is the first generalist model that performs so well on so many different tasks, and it’s extremely promising for the field. It was trained on 604 distinct tasks with varying modalities, observations, and action specifications, making it the perfect generalist.
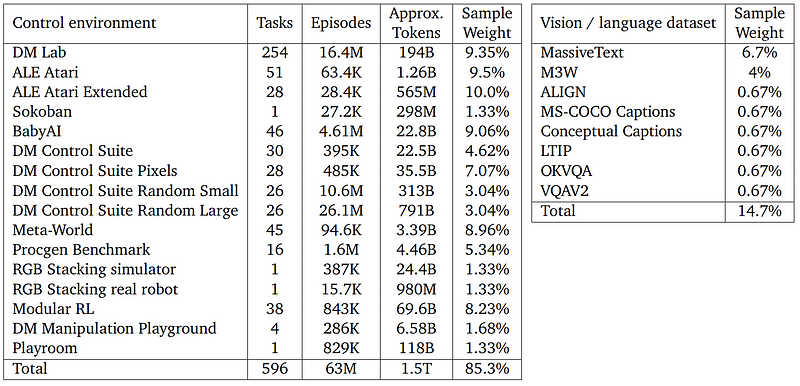
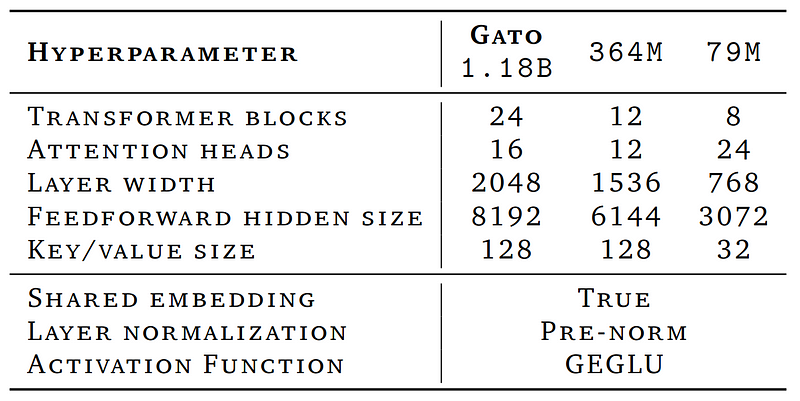
And as I said, it does all that with the same network and weights (and before you ask, it only needs 1.2 billion parameters compared to GPT-3, which requires 175 billion of them!). It’s not a trap where you have to re-train or fine-tune it for all tasks.
You can send both an image and text, and it will work. You can even add in a few movements from a robot arm! The model can decide which type of output to provide based on its context, ranging from text to discrete actions in an environment.
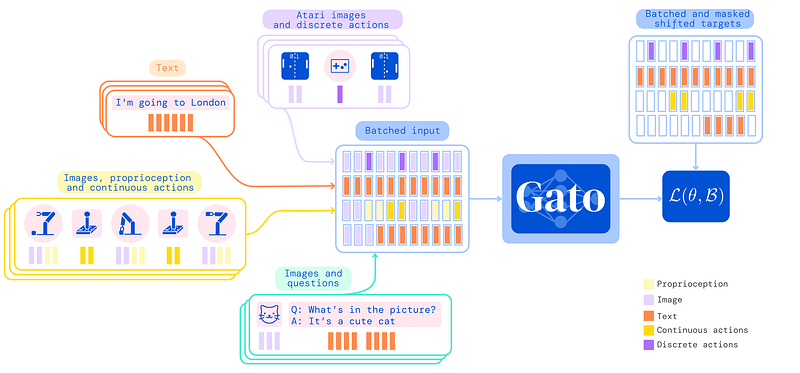
This is possible because of their tokenization process. Tokenization is when you prepare your inputs for the model, as they do not understand text or images by themselves. Language models and Gato took the total number of subwords, for example, 32000, and each word has a number assigned to it.
For images, they follow the ViT patch embedding using a widely used ResNet block, as we covered in a previous video. We also tokenize the button presses as integer numbers for Atari games or discrete values.
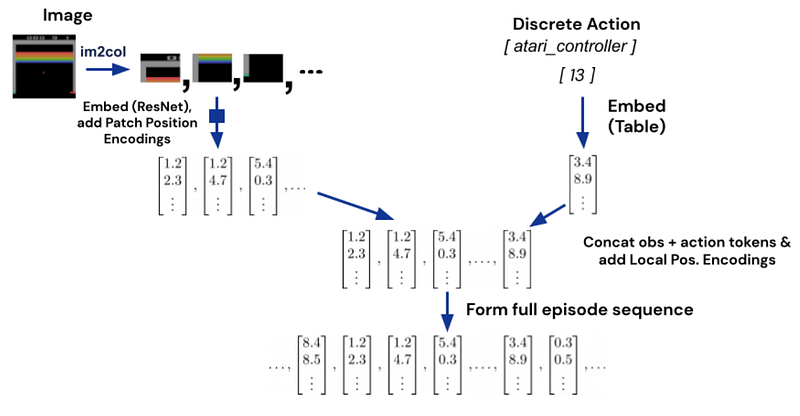
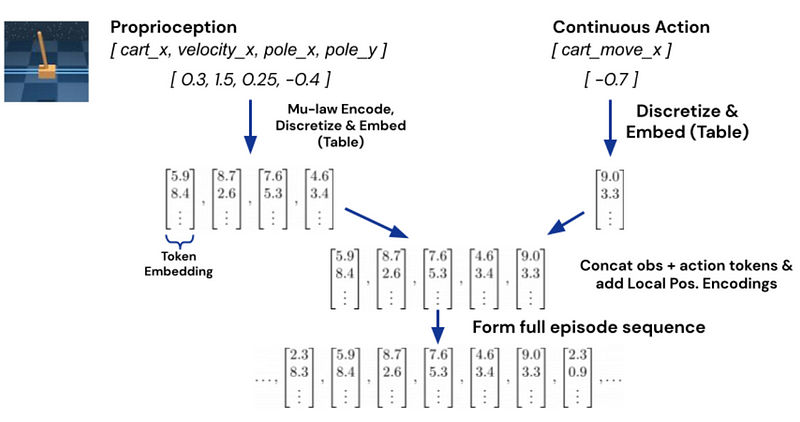
Finally, for continuous values like proprioceptive inputs we talked about with the robotic arms, they encoded the different tracked metrics into float numbers and added them after the text tokens.
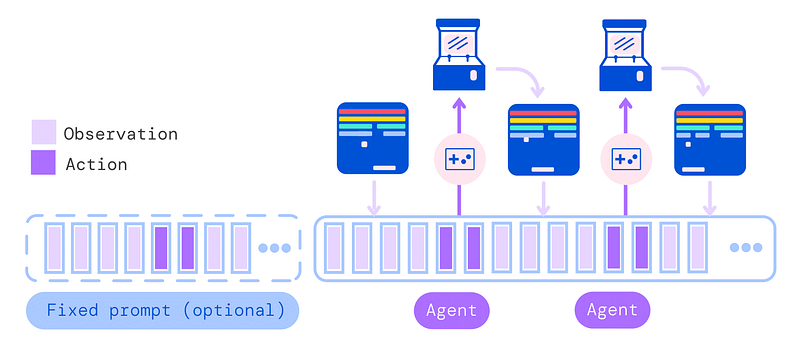
Using all those different inputs, the agent adapts to the current task to generate appropriate outputs. During training, they use prompt conditioning as in GPT-3 with previously sampled actions and observations.
The progress in generalist RL agents in the last years has been incredible and came mainly from Deepmind. One could say that they are moving the needle closer to general AI (AGI) or human-level intelligence (if we can finally define it). I love how many details they gave in their paper. I’m excited to see what they will do, or what other people will do, using this model’s architecture!
The link to the paper for more information about the model is in the description.
I hope you enjoyed this short article. I just saw this news when I woke up and had to cover it before doing anything else in my day. It is just too exciting!
I will see you next week with another amazing paper!
References
►Watch the video: https://youtu.be/xZKSWNv6Esc
►Deepmind’s blog post: https://www.deepmind.com/publications/a-generalist-agent
►Paper, Reed S. et al., 2022, Deemind: Gato. https://storage.googleapis.com/deepmind-media/A%20Generalist%20Agent/Generalist%20Agent.pdf
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/