

Watch the video!
This is eDiffi, the new state-of-the-art approach in image synthesis.
It generates better-looking and more accurate images than all previous approaches like DALLE 2 or Stable Diffusion. eDiffi better understands the text you send and is more customizable, adding a feature we saw in a previous paper from NVIDIA: the painter tool.

Results from the eDiffi paper.
As they say, you can paint with words. In short, this means you can enter a few subjects and paint in the image what should appear here and there, allowing you to create much more customized images compared to a random generation following a prompt. This is the next level, enabling you to pretty much get the exact image you have in mind by simply drawing a horrible quick sketch — something even I can do!

Results from the eDiffi paper.
As I mentioned, the results are not only SOTA and better looking than Stable Diffusion — but it also is way more controllable. Of course, it’s a different use case as it needs a bit more work and a clearer idea in mind for creating such a draft, but it’s definitely super exciting and interesting. It is also why I wanted to cover it on my channel since it’s not merely a better model but also a different approach with much more control over the output.
The tool isn’t available yet, but I sure hope it will be soon. By the way — you should definitely follow me on Medium and my newsletter if you like this kind of article and would like to have access to easily digestible news on this heavily complicated field!
Another way in which they allow you to have more control in this new model is by using the same feature we saw but differently. Indeed, the model generates images guided by a sentence, but it can also be influenced using a quick sketch — so it basically takes an image and a text as inputs.
This means you can also do other stuff as it understands images. Here, they leverage this capability by developing a style transfer approach where you can influence the style of the image generation process giving an image with a particular style along with your text input. This is super cool and just look at the results. It’s kind of incredible. Beating both SOTA style transfer models AND image synthesis models with a single approach.
Now the question is: how could NVIDIA develop a model that creates better-looking images,
enable more control over both the style and the image structure as well as better understanding and representing what you actually want.
Well, they change the typical diffusion architecture in two ways.
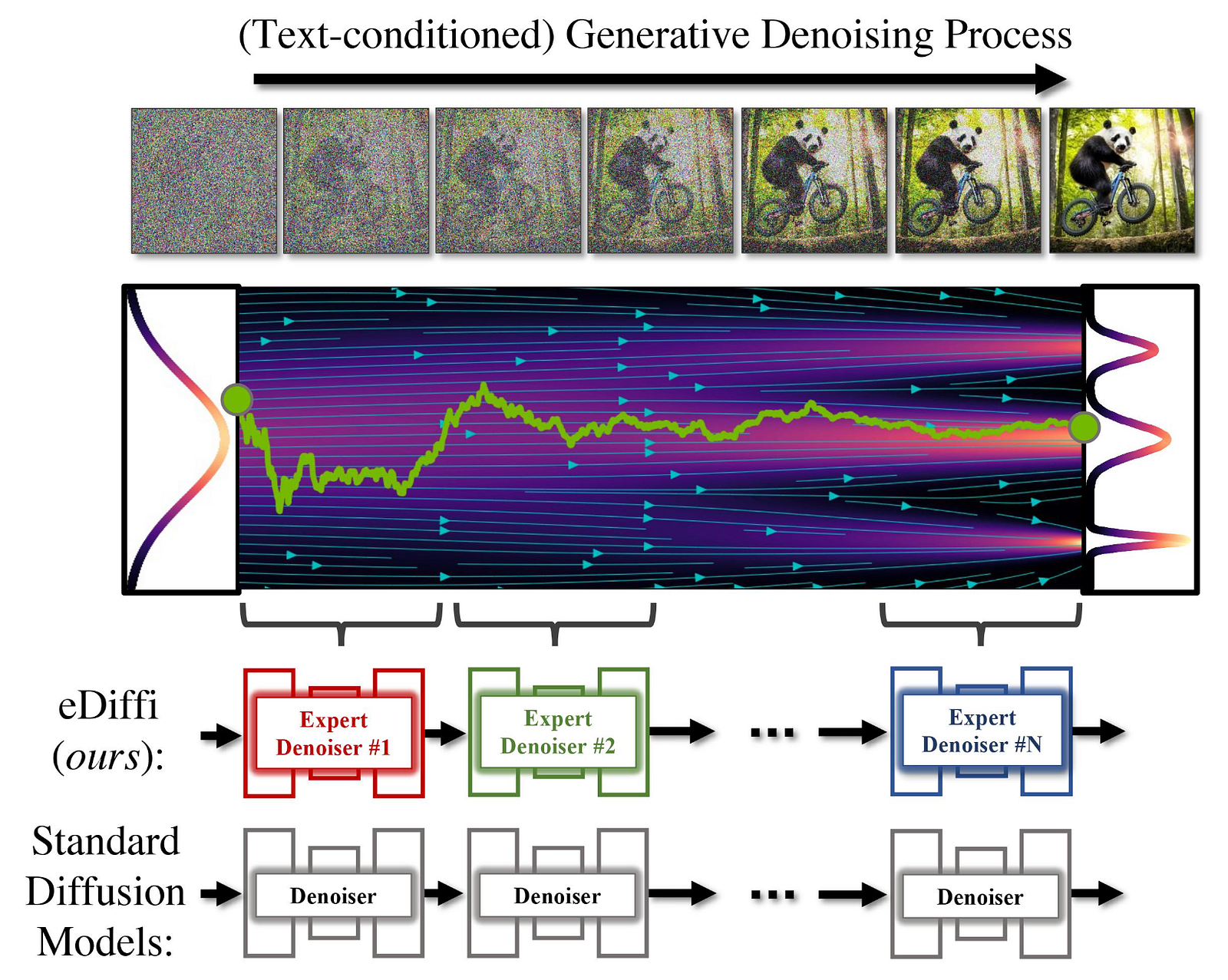
eDiffi pipeline. Image from the eDiffi paper.
First, they encode the text using two different approaches that I already covered on the channel, which we refer to as CLIP and T5 encoders. This means they will use pre-trained models to take text and create various embeddings focusing on different features as they were trained and behaved differently. Embeddings are just representations maximizing what the sentence actually means for the algorithms, or the machine, to understand it. Regarding the input image, they just use the CLIP embedding as well, basically encoding the image so that the model can understand it as well, which you can learn more about in my other videos covering generative models, as they are pretty much all built on CLIP.
This is what allows them to have more control over the output as well as process text and images rather than only text.
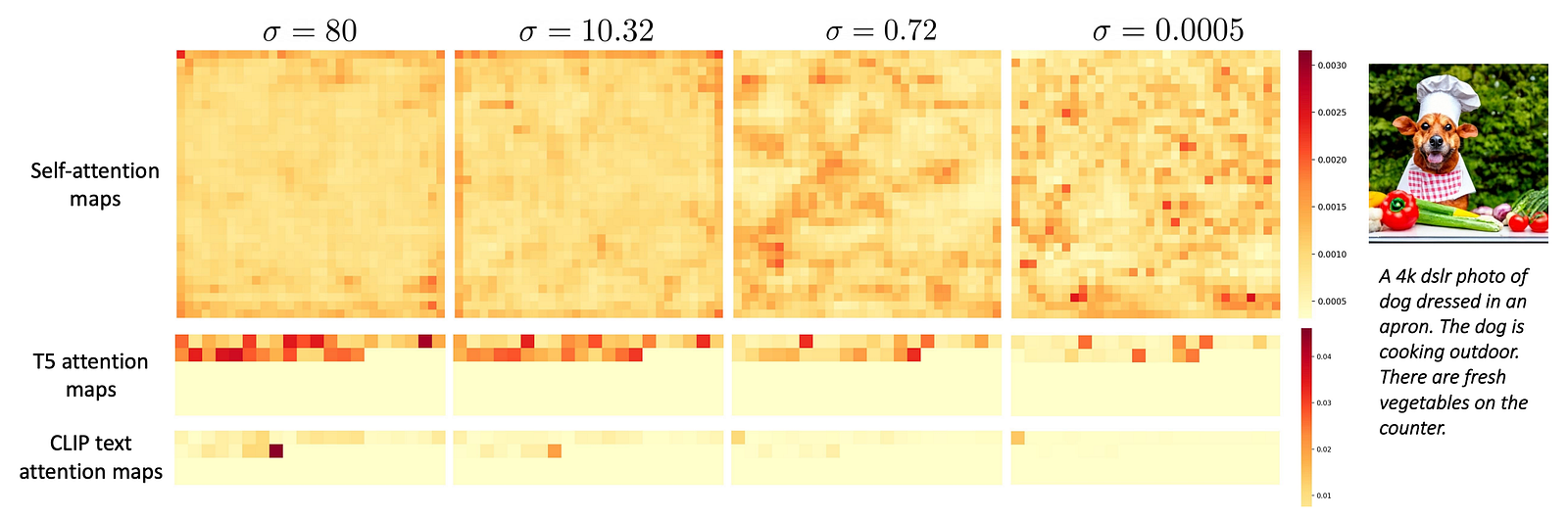
Attention maps visualized for different steps of the process. Image from the eDiffi paper.
The second modification is using a cascade of diffusion models instead of re-using the same iteratively, as we usually do with diffusion-based models. Here, they use models trained for the specific part of the generative process. Meaning that each model does not have to be as general as the regular diffusion denoiser. Since it has to focus on a specific part of the process, it can be much better at it. They used this approach because they observed that the denoising model seemed to use the text embeddings a lot to orient its generation towards the beginning of the process and then use it less and less to focus on output quality and fidelity. This naturally brings the hypothesis that re-using the same denoising model throughout the whole process might not be a good idea since it automatically focuses on different tasks, and we know that a generalist is far from the expert level at all tasks. Why not use a few experts instead of one generalist to get much better results?
This is why they call them “denoising experts” and the main reason for this improved performance in quality and faithfulness. The rest of the architecture is pretty similar to other approaches upscaling the final results with other models to get a high-definition final image.
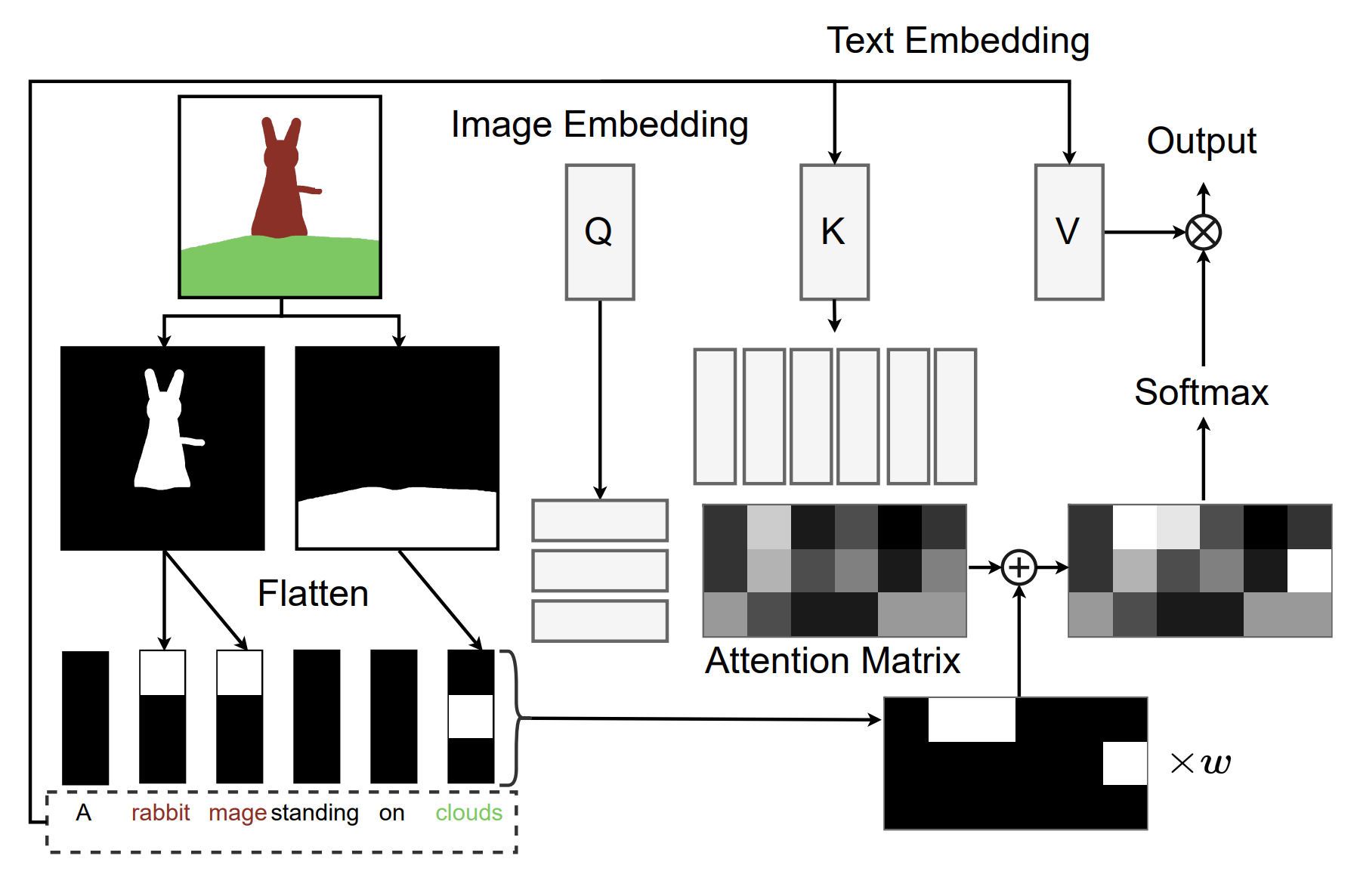
(caption and image from the eDiffi paper) Illustration of the proposed paint-with-words method. The user can control the location of objects by selecting phrases (here “rabbit mage” and “clouds”), and painting them on the canvas. The user-specified masks increase the value of corresponding entries of the attention matrix in the cross-attention layers.
Lastly, for the input drawings, they simply take the individual masks of each object drawn and associate it to the words in question in the embedded text representation, similar to a weighting system in the cross-attention layers of the regular network, giving more value to specific parts of the text.
The image and video synthesis fields are just getting crazy nowadays, and we are seeing impressive results coming out every week. I am super excited for the next releases, and I love to see different approaches with both innovative ways of tackling the problem and also going for different use cases.
As a great person once said, “What a time to be alive!”
I hope you liked this quick overview of the approach, which is a bit more high-level than what I usually do, as it takes most parts I already covered in numerous videos and change them to act differently. I invite you to watch my stable diffusion video to learn more about the diffusion approach and read NVIDIA’s paper to learn more about this specific approach and its implementation.
I will see you next week with another amazing paper!
References
►Read the full article: /ediffi/
► Balaji, Y. et al., 2022, eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers, https://arxiv.org/abs/2211.01324
►Project page: https://deepimagination.cc/eDiffi/
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/