Galactica: What is it and What Happened?
Galactica, Meta AI's most recent model: The AI Scientist


Watch the video
On November 15th, MetaAI and Papers with Code announced the release of Galactica, a game-changer, open-source large language model trained on scientific knowledge with 120 billion parameters.
As one of my friends shared on Twitter, the model can write whitepapers, reviews, Wikipedia pages, and code. It knows how to cite and how to write equations. It’s kind of a big deal for AI and science.
On November 17th, Galactica was shut down.
Why? Because, as with all deep learning models, it didn’t understand the task at hand and was wrong in many cases. This shouldn’t be an issue, especially if we add a warning saying the model may be wrong and not to trust it blindly. Just like nobody trusted Wikipedia, we couldn’t put this as a reference in High School projects. The issue is that Galactica was wrong or biased but sounded right and authoritative.
Still, the model is available to researchers, and I believe it is important to keep it open-sourced.
As another of my friend shared, all the drama around the new model seems a bit excessive. Of course, the model isn’t perfect, just like all others that are currently available online. We need it online to test its limitations, work on it and improve it. We should see these kinds of publications as students and allow for mistakes and improvements without fear of being shut down or canceled.
Anyways, we are not here to discuss that. Hopefully, it will be back online soon.
We are here to see what Galactica is, or was, and how it could achieve writing papers, reviews, code, and more…
Basically, Galactica is a large language model with a size comparable to GPT-3, but specialized on scientific knowledge. More precisely, it was trained on a large and curated corpus of scientific knowledge, including over 48 million papers, textbooks and lecture notes, millions of compounds and proteins, scientific websites, encyclopedias, and more. Data, which they highlight, were of high-quality and highly curated, which is one of the big differences with GPT-3.
So, in theory, Galactica contains pretty much all of humanity’s scientific knowledge. Imagine having an amazing memory and the time to read millions of research, remembering most of it.
Well, this is Galactica. It seems like its memory isn’t so good after all, and it mixes everything even though we could assume most information present in the training dataset was accurate. Even considering all the biases and failures, Galactica stays pretty powerful and outperforms pretty much all other approaches for science-related tasks.
It’s just not enough for a product we can have confidence in. Still, it’s worth understanding how it works, especially because it will come back even more powerful pretty soon.

As we mentioned, Galactica is a large language model, similar to GPT-3 or BLOOM, specifically trained for, as they say, “organize science”. There’s also a lot of engineering going on in this model, allowing so much versatility in its inputs and outputs, like special tokenization of citations or protein sequences, which you can learn more about in their paper linked below. Their tokenization effort is by far the biggest contribution of this work. Tokenization basically means the way the model will see the data instead of words, math, or shapes that we see and understand. I’ll actually share an article on embedding and tokenization later this week, so if that sounds interesting, stay tuned for that and follow me to not miss it!
So except this weird tokenization and pre-processing steps, what is Galactica, and what does it do after taking the words or different scientific inputs and preparing it for the model doing tokenization?

No surprise, Galactica is yet another Transformer-based architecture, like GPT-3, with a couple of variations, including the tokenization differences. So I definitely invite you to read one of the many articles I or some of my friends made covering the Transformer architectures as I won’t get into how it works once again.
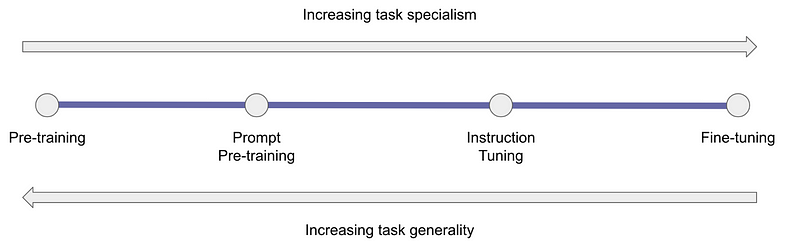
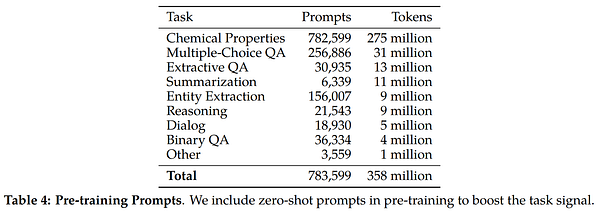
The second major difference between Galactica and other large language models is what they call the prompt pre-training. This means that they will include prompts extracted from the training datasets alongside the data itself, which has been shown to “maximize the generality of the model while boosting performance on some tasks of interest.”
And that’s pretty much it!
As I said, the architecture is very similar to what you already know, and mostly the training and pre-processing schemes vary, which shows that the model isn’t everything, but how we pre-chew the data for it actually might matter even more. You can basically see the difference between GPT-3 and Galactica as the same student with a bad science teacher vs. a good one. It has the same capabilities and resources. The teacher just made it more accessible and understandable for him.
Of course, this was just an overview of the paper, and I strongly recommend reading it. There are tons of details about the multiple engineering tricks they’ve implemented, along with results analysis, details on all the tasks they tackled using the model and how it understood the input data and its predictions, its limitations, biases, and more
I hope you enjoyed this article, and I will see you next week with another amazing paper and a special article covering what embeddings are!
References
►Taylor et al., 2022: Galactica, https://galactica.org/
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/