

The short version
X-CLIP recognized videos by extending a pretrained language-image model across time. The 2022 method encoded each frame with a vision Transformer, used attention to exchange information among frames, then aligned the resulting video representation with text. This let one architecture handle several video recognition tasks, but it compared learned representations rather than demonstrating human-like understanding.
Watch the video
We’ve seen AI generate text, then generate images and most recently even generate short videos, even though they still need work. The results are incredible when you think that no one is actually involved in the creation process of these pieces and it only has to be trained once to then be used by thousands of people like stable diffusion is. Still, do these models really understand what they are doing? Do they know what the picture or video they just produced really represents? What does such a model understand when it sees such a picture or, even more complex, a video?

Result example from the paper.
Let’s focus on the more challenging of the two and dive into how an AI understands videos through a task called general video recognition, where the goal is for a model to take videos as inputs and use text to describe what’s happening in the short video.
General video recognition is one of the most challenging tasks in understanding videos. Yet, it may be the best measure of a model’s ability to get what’s happening. It is also the basis behind many applications relying on a good understanding of videos like sports analysis or autonomous driving. But what makes this task so complex? Well, there are two things:
- We need to understand what is shown, meaning each frame or each image of a particular video.
- We need to be able to say what we understand in a way humans understand, which means words.
Fortunately for us, the second challenge has been tackled numerous times by the language community, and we can take over their work. More precisely, we can take what people from the language-image field have done with models like CLIP or even stable diffusion, where you have a text encoder and image encoder that learns to encode both types of inputs into the same kind of representation. This way, you can compare a similar scene to a similar text prompt by training the architecture with millions of image-caption examples. Having both text and images encoded in a similar space is powerful because it takes much less space to perform computations, and it allows us to compare text to images easily. Meaning that the model still doesn’t understand an image or even a simple sentence, but it can understand if both are similar or not. We are still far from intelligence, but that’s pretty useful and good enough for most cases.
Now comes with the biggest challenge here: videos. And for that, we’ll use the approach from Bolin Ni and colleagues in their recent paper “Expanding Language-Image Pretrained Models for General Video Recognition”.
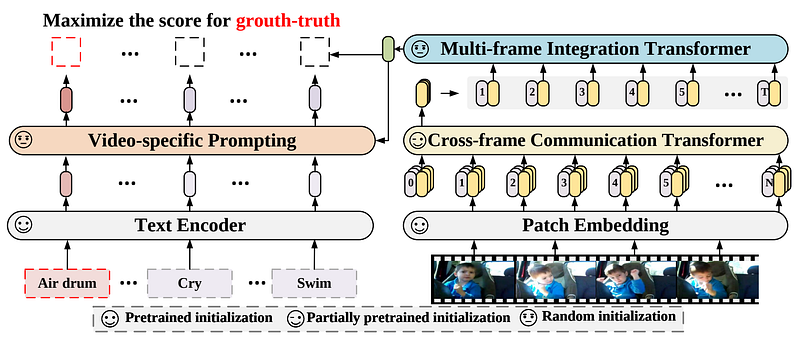
Model Overview. Image from the paper.
Videos are much more complex than images due to the temporal information, meaning the multiple frames and the fact that each frame is linked to the next and the previous one with coherent movement and actions. The model needs to see what happened before, during, and after each frame to have a proper understanding of the scene.
It’s just like on YouTube. You cannot really skip 5 seconds forward in short videos as you will miss valuable information.
In this case, they take each frame and send them into the same image encoder we just discussed using a vision transformer-based architecture to process them into a condensed space using attention.
If you are not familiar with vision transformers, or the attention mechanism, I will invite you to watch the video I made introducing them.
Once you have your representation for each frame, you can use a similar attention-based process to have each frame communicate together and allow your model to exchange information between frames and create a final representation for the video. This information exchange between frames using attention will act as some sort of memory for your model to understand the video as a whole rather than a couple of random images together.
Finally, we use another attention module to merge the text encodings of the frames we had with our condensed video representation.

Result example from the paper.
And voilà!
This is one way an AI understands a video. Of course, this was just an overview of this great paper by Microsoft Research serving as an introduction to video recognition and I invite you to read the paper for a better understanding of their approach.
Thank you for reading through the entire article and I will see you next week with another amazing paper!
Louis
References
►Read the full article: /general-video-recognition/
►Ni, B., Peng, H., Chen, M., Zhang, S., Meng, G., Fu, J., Xiang, S. and Ling, H., 2022. Expanding Language-Image Pretrained Models for General Video Recognition. arXiv preprint arXiv:2208.02816.
►Code: https://github.com/microsoft/VideoX/tree/master/X-CLIP
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
FAQ
What is general video recognition?
It identifies visual content and temporal activity across a video rather than classifying only one still frame.
Why is video harder to understand than an image?
A video adds motion, ordering, duration, and relationships between frames to the spatial content within each frame.
What must a video model learn first?
It needs useful features for the objects and scenes shown in individual frames.
Does matching text and video mean the model understands them like a person?
No. Similarity is a useful learned relationship, but it does not establish human-like comprehension.
Why combine spatial and temporal features?
Spatial features describe what appears, while temporal features describe how it changes and what action occurs.