Google Brain's Answer to Dalle-e 2: Imagen
An AI that creates photorealistic images from input text better than Dall-e 2!


Watch the video
If you thought Dall-e 2 had great results, wait until you see what this new model from Google Brain can do. Dalle-e is amazing but often lacks realism, and this is what the team attacked with this new model called Imagen. They share a lot of results on their project page as well as a benchmark, which they introduced for comparing text-to-image models, where they clearly outperform Dall-E 2, and previous image generation approaches. See the results in the video above!
This benchmark is super cool as we see more and more text-to-image models, and it’s pretty difficult to compare the results — unless we assume the results are really bad, which we often do. But this model, and dall-e 2, definitely defy these odds.
tl;dr: it is a new text-to-image model that you can compare to Dalle-E 2 with more realism as per human testers.

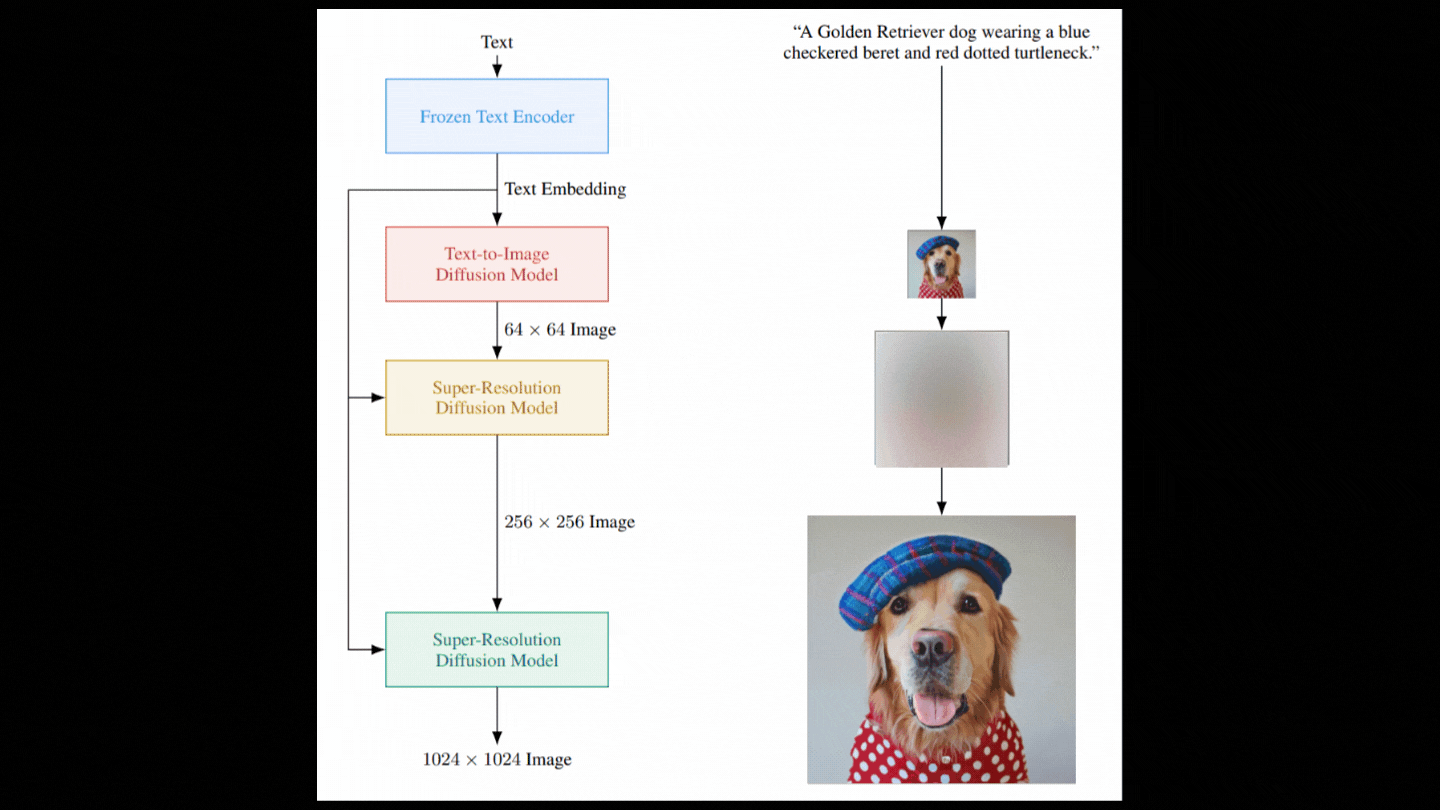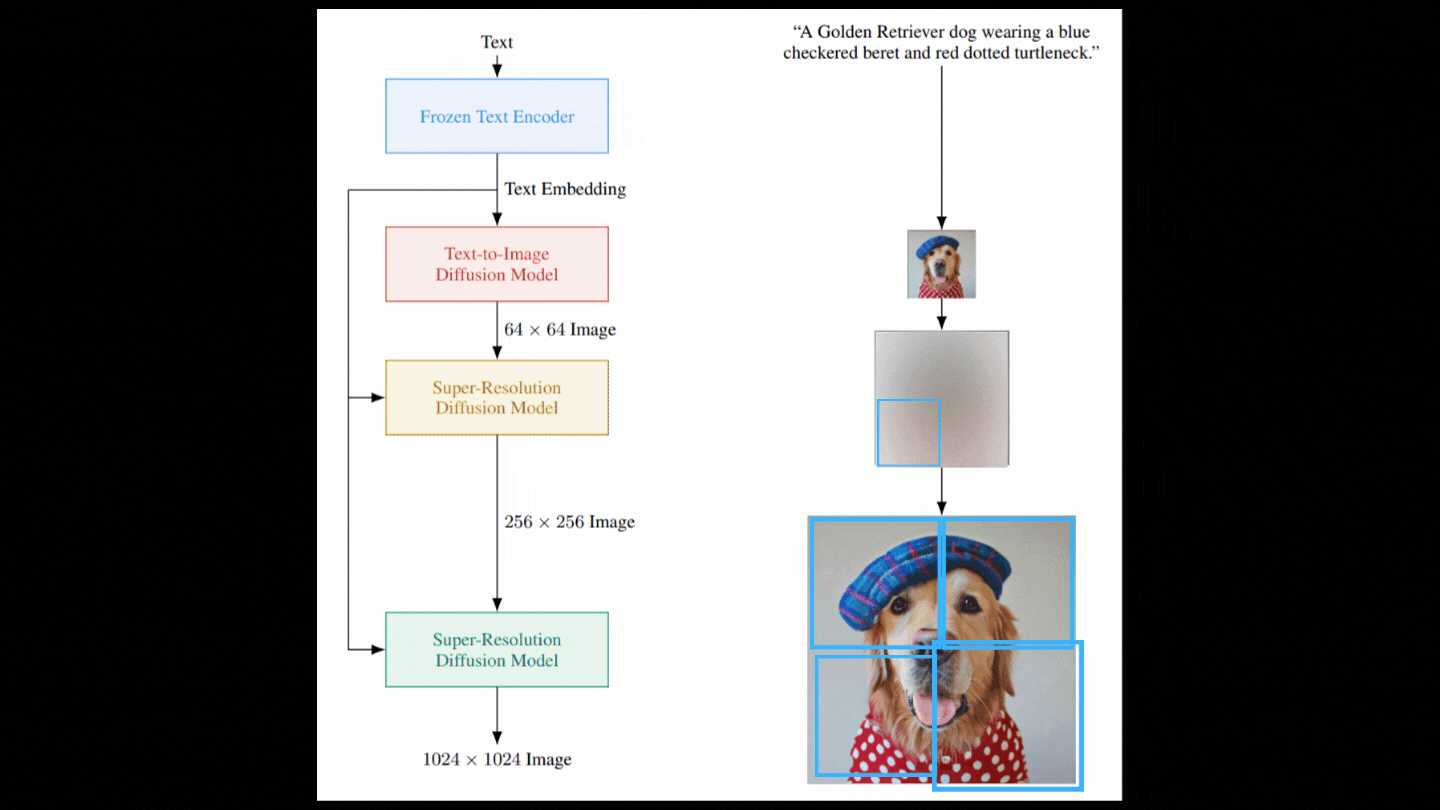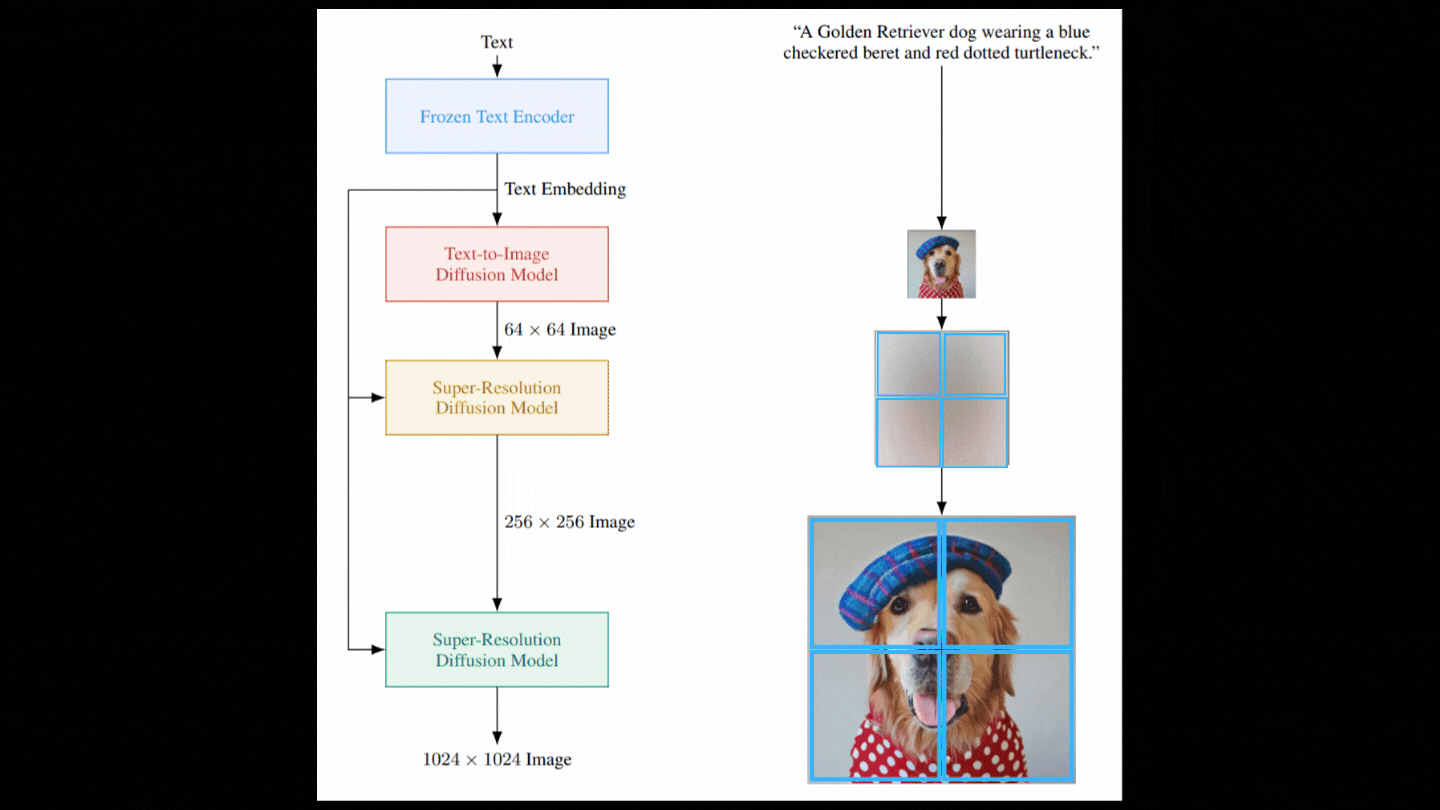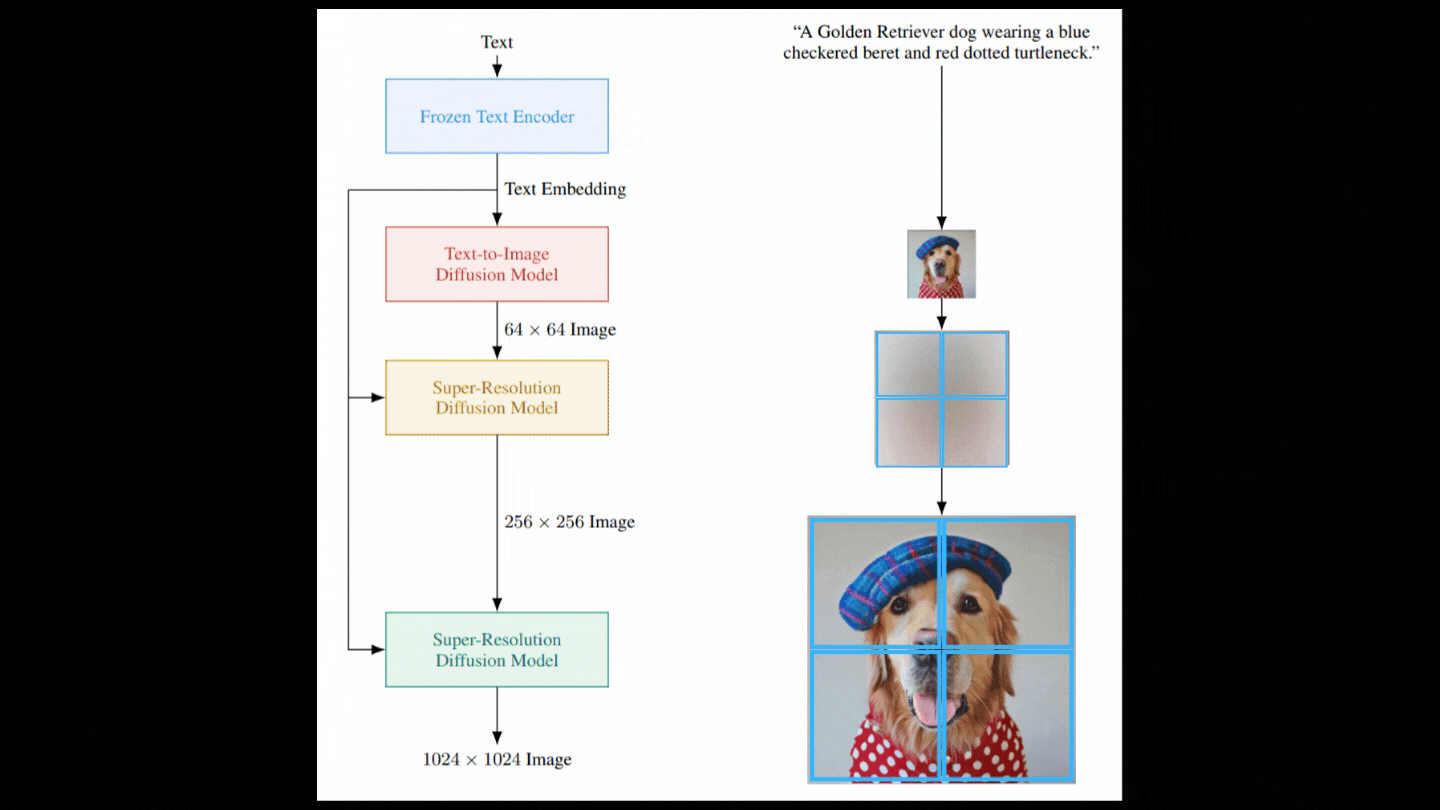
So just like Dall-E that I covered a month ago, this model takes text like “A golden Retriever dog wearing a blue checkered beret and red dotted turtle neck” and tries to generate a photorealistic image out of this weird sentence. The main point here is that Imagen can not only understand text, but it can also understand the images it generates since they are more realistic than all previous approaches.
Of course, when I say understand, I mean its own kind of understanding that is different from ours. The model doesn’t really understand the text or the image it generates. It definitely has some kind of knowledge about it, but it mainly understands how this particular kind of sentence with these objects should be represented this way using pixels on an image. But I’ll concede that it sure looks like it understands what we send it when we see those results!

Obviously, you can trick it with some really weird sentences that couldn’t look realistic, like this one, but it sometimes beats your own imagination and just creates something amazing.

Still, what’s even more amazing is how it works using something I never discussed on the channel; a diffusion model. But before using this diffusion model, we first need to understand the text input. And this is also the main difference with Dall-e. They used a huge text model, similar to GPT-3, to understand the text as best as an AI system can. So instead of training a text model along with the image generation model, they simply use a big pre-trained model and freeze it so that it doesn’t change during the training of the image generation model. From their study, this led to much better results, and it seemed like the model understood text better.
So this text module is how the model understands text, and this understanding is represented in what we call encodings, which is what the model has been trained to do on huge datasets to transfer text inputs into a space of information that it can use and understand. Now, we need to use this transformed text data to generate the image, and, as I said, they used a diffusion model to achieve that.
But what is a diffusion model?
Diffusion models are generative models that convert random Gaussian noise like this into images by learning how to reverse gaussian noise iteratively. They are powerful models for super-resolution or other image-to-image translations and, in this case, use a modified U-Net architecture which I covered numerous times in previous videos, so I won’t enter into the architectural details here.

Basically, the model is trained to denoise an image from pure noise, which they orient using the text encodings and a technique called Classifier-free guidance which they say is essential for the quality of the results and clearly explained in their paper. I’ll let you read it for more information on this technique with the link in the references below.
So now we have a model able to take random Gaussian noise and our text encoding and denoise it with guidance from the text encodings to generate our image. But as you see in the figure showing the model above, it isn’t as simple as it sounds. The image we just generated is a very small image as a bigger image would require much more computation and a much bigger model, which are not viable. Instead, we first generate a photorealistic image using the diffusion model we just discussed and then use other diffusion models to improve the quality of the image iteratively. I already covered super-resolution models in past videos, so I won’t enter into the details here, but let’s do a quick overview. Once again, we want to have noise and not an image, so we corrupt this initially generated low-resolution image with again some Gaussian noise, and we train our second diffusion model to take this modified image and improve it.
Then, we repeat these two steps with another model but this time using just patches of the image to do the same upscaling ratio and stay computationally viable.
And voilà! We end up with our photorealistic high-resolution image!

Of course, this was just an overview of this exciting new model with really cool results. I definitely invite you to read their great paper for a deeper understanding of their approach and a detailed results analysis.
And you, do you think the results are comparable to dall-e 2? Are they better or worse? I sure think it is dall-e’s main competitor as of now. Let me know what you think of this new Google Brain publication and the explanation.
I hope you enjoyed this article, and if you did, please take a second to leave a like under the video to support my work and follow the blog to stay up-to-date with exciting AI news!
I will see you next week with another amazing paper!
References
►Watch the video: https://youtu.be/qhtYPhPWCsI
►Paper: Saharia et al., 2022, Imagen — Google Brain, https://gweb-research-imagen.appspot.com/paper.pdf
►Project link: https://gweb-research-imagen.appspot.com/
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/