An AI that Automatically Summarizes your Documents
A new model for automatically generating summaries using machine learning, released in Google Docs that you can already use!


Watch the video
Do you find it hard to quickly summarize a movie you just watched or a book you read a few weeks ago? Sometimes you love a book, and, if you can manage to remember its content, which I often can’t, you may end up boring your friend by talking for an hour describing the many chapters and important parts while your friend just wants to have a quick and concise summary. This is because doing a great summary is challenging, even for us, but necessary. How useful it is to be able to quickly know what the book is about before buying it, or simply to help you go through all your emails and documents in seconds.
You need to have a great understanding of a book, movie, or any content you are trying to summarize to do it well. Omit all unnecessary information while keeping the essential. Making something as concise as possible can be really complicated or even impossible.
Here, I try to explain research in a few minutes, and I often can’t manage to make it shorter than 5 minutes, even if it’s only a summary of a 20-page piece. It requires hours of work and fine-tuning, and now I may be replaced by an AI that does that better in milliseconds.
Indeed, Google recently announced a new model for automatically generating summaries using machine learning, released in Google Docs that you can already use.
The model will try to understand the whole document and generate a short summary of the piece — something some movie professionals clearly still can’t do.
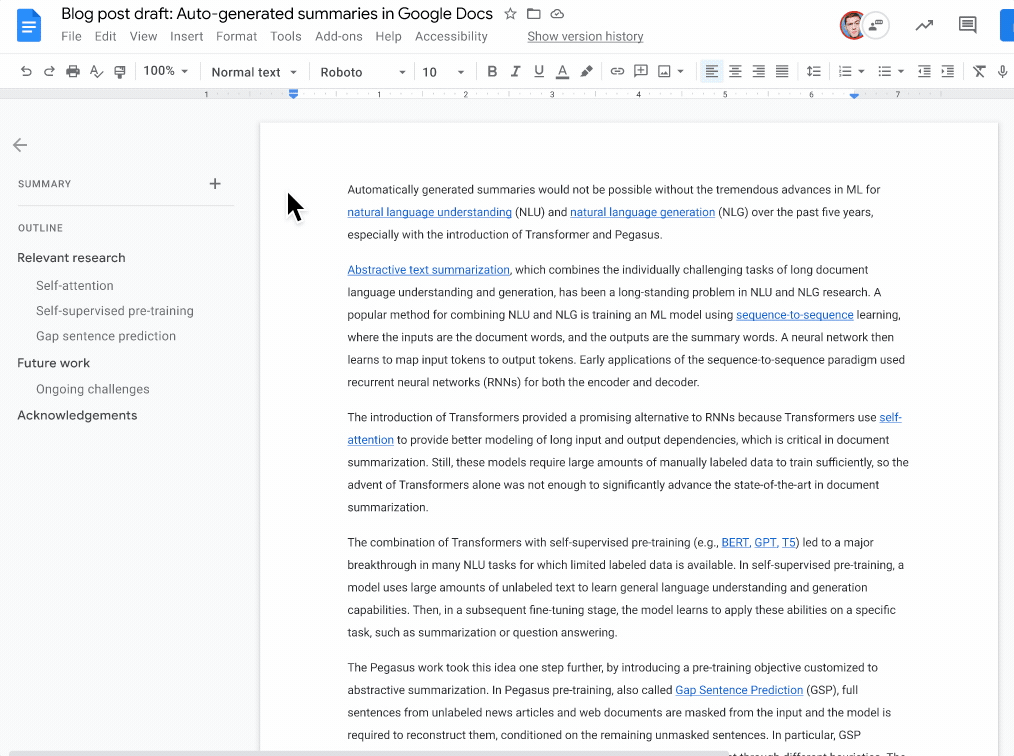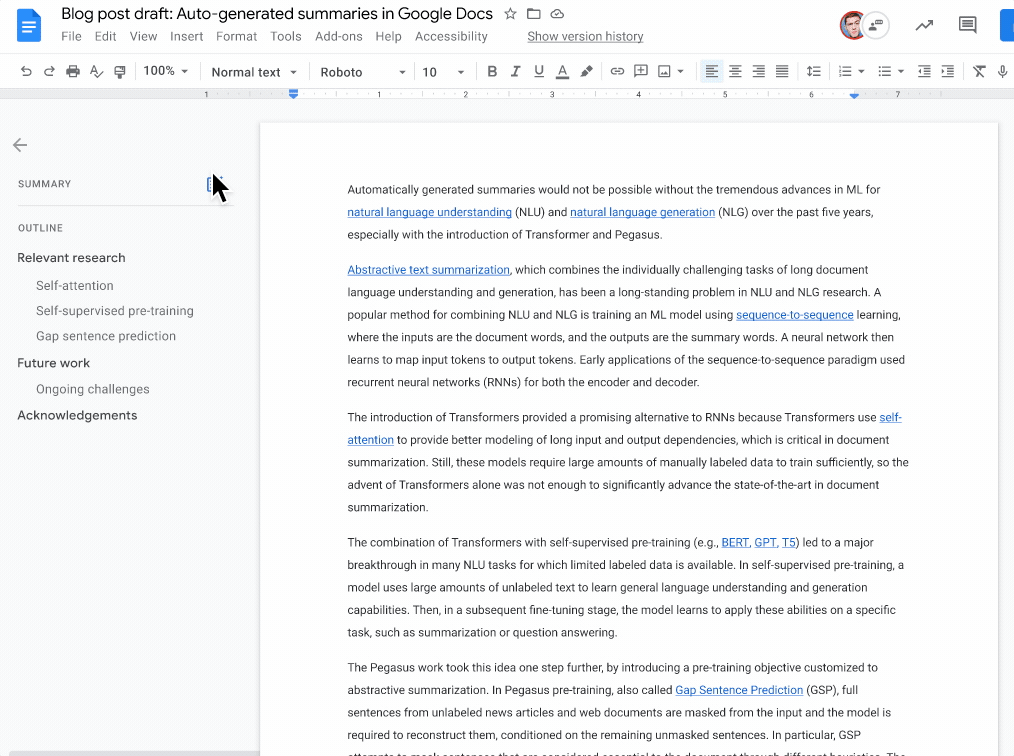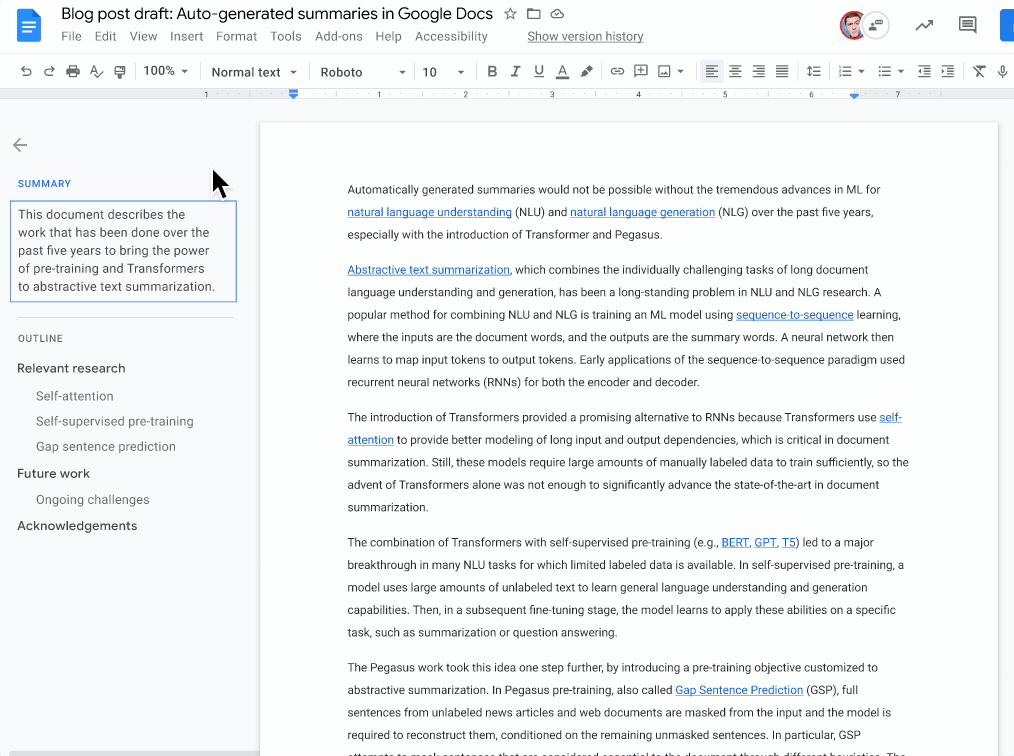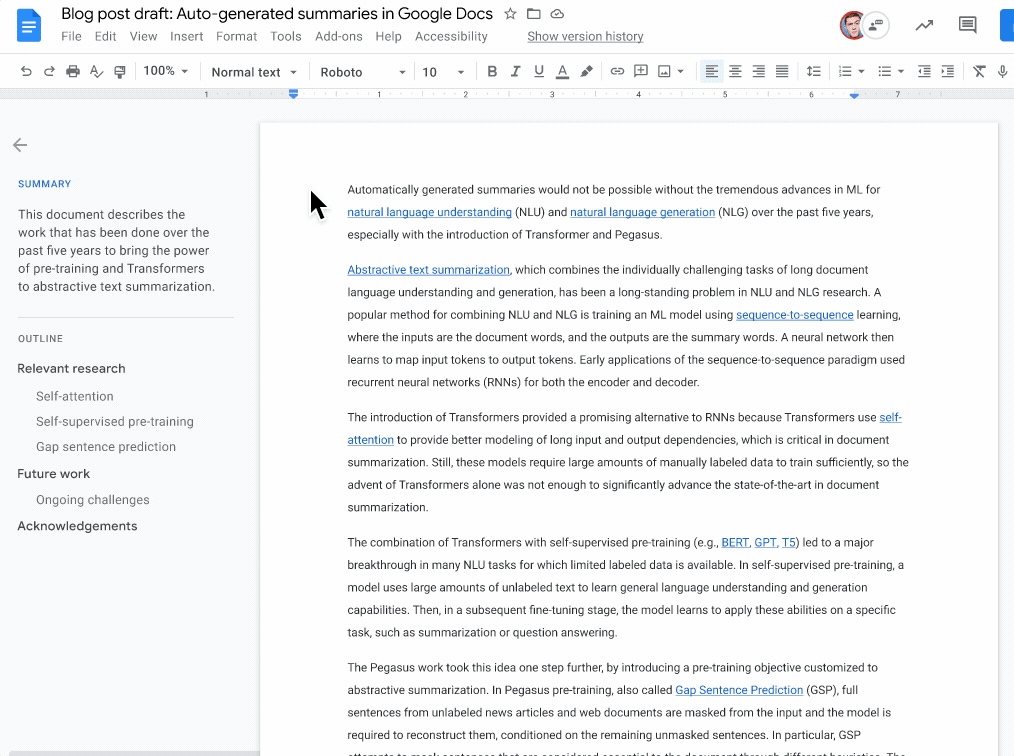
The model needs to achieve two things:
- Understand the text in the document called Natural Language Understanding.
- Generate coherent sentences using a natural language. Or, in other words, perform Natural Language Generation.
But how can you achieve that
You guessed it… With a lot of data and compute power! Luckily enough, this is Google Research.
They trained their model to replicate our thought process for generating summaries using way too many documents with manually-generated summaries. Seeing all these examples, the model does like any good student and ends up being able to generate relatively good summaries for similar documents as it has seen during its training phase. You can see why we need good-quality data here. The model will learn from them. It may only be as good as the data that was used for training it.
It would be like having a really bad coach that doesn’t know anything about basketball trying to teach a new player. How could this new player become any good if the coach doesn’t know anything about the sport? The newcomer’s talent won’t be optimized and might be wasted only because of the poor coaching.
The challenge comes with generalizing to new documents. Generalizing is sometimes even difficult for students that only learned how to perform the given examples, but did not understand how to apply the formulas. It is the same thing here. The model faces difficulties as it cannot remember all documents and summaries by heart. It HAS to understand them, or, at the least, know which words to put its attention on in order to produce a summary that reflects the document well. The latter will most likely happen as the model doesn’t really understand the document, it only understands how to perform the task, which is unfortunately still far from human-level intelligence, but well enough for such a task.
I just mentioned “attention”. Well, this was not a coincidence. Attention may be the most important concept behind this model. Indeed, just like GPT-3, this new model also uses the Transformer architecture and attention mechanisms. This is where high computation is required. As you know, transformers are big and powerful networks, but most time a bit too big for fast and efficient tools that need to be available online in seconds. Transformers’ computation complexity also scales with the input size, which means that the longer the input, the heavier the computation will be, causing big issues when you want to summarize a whole book.

GPT-3 works well for small inputs like question answering tasks, but the same architecture won’t be able to process whole books efficiently. Instead, they had to use some tricks in order to have a smaller and more efficient model while keeping high-quality results. This optimization was achieved by merging Transformers with RNNs, which are two concepts I explained in previous videos that I highly recommend watching for a better understanding. Both videos are linked in the description below.
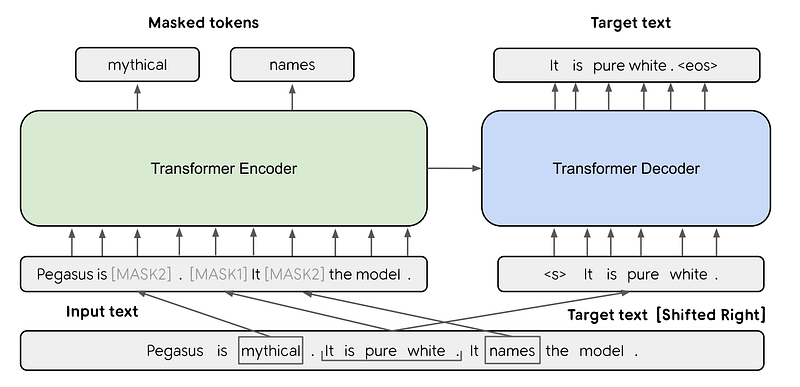
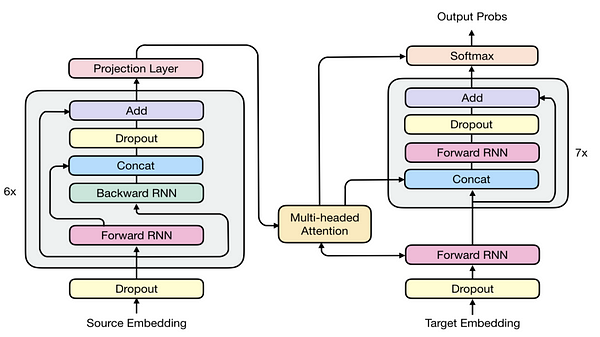
In short, it will act similar to GPT-3, which you should understand by now from my video about it, but with a smaller version of the model, iterating over and over until the model finishes the book. The transformer part of the architecture will be responsible for “understanding” a small section of the text and producing an encoded version of it. The RNN will be responsible for stacking and keeping this knowledge in memory, iterating through the whole book to end up with the most concise way of summarizing its content. Working together, the attention mechanism added to the recurrent architecture will be able to go through long documents and find the most important features to mention in the summary, as any human would do.

Of course, the model is not perfect, since even professional writers aren’t perfect at summarizing their work, but the results are quite impressive and produced extremely efficiently. I’d strongly recommend trying it for yourself in Google Docs to make up your mind about it.
And voilà!
This is how Google Docs automatically summarize your documents with their new machine learning-based model. I hope you enjoyed the article! If so, please take a second to leave a comment and follow my work. Let me know your thoughts on this new model. Will you use it?
Thank you for reading until the end, and I will see you next week with another amazing paper!
References
►Google’s blog post: https://ai.googleblog.com/2022/03/auto-generated-summaries-in-google-docs.html
►GPT-3 video: https://youtu.be/gDDnTZchKec
►Attention video: https://youtu.be/QcCJJOLCeJQ
►What are RNNs?: https://youtu.be/Z0pb3LjeIZg
►[1] Zhang, J., Zhao, Y., Saleh, M. and Liu, P., 2020, November. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning (pp. 11328–11339). PMLR.
►[2] Chen, M.X., Firat, O., Bapna, A., Johnson, M., Macherey, W., Foster, G., Jones, L., Parmar, N., Schuster, M., Chen, Z. and Wu, Y., 2018. The best of both worlds: Combining recent advances in neural machine translation. arXiv preprint arXiv:1804.09849.
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/