

Watch the video and support me on YouTube
Say goodbye to complex GAN and transformer architectures for image generation. This new method by Chenling Meng et al. from Stanford University and Carnegie Mellon University can generate new images from any user-based inputs. Even people like me with zero artistic skills can now generate beautiful images or modifications out of quick sketches. It may sound weird at first, but by just adding noise to the input, they can smooth out the undesirable artifacts, like the user edits, while preserving the overall structure of the image. So the image now looks like this, complete noise, but we can still see some shapes of the image and stroke, and specific colors. This new noisy input is then sent to the model to reverse this process and generate a new version of the image following this overall structure. Meaning that it will follow the overall shapes and colors of the image, but not so precisely that it can create new features like replacing this sketch with a real-looking beard.

SDEdit examples. SDEdit, Chenlin Meng et al., 2021
In the same way, you can send a complete draft of an image like this, add noise to it, and it will remove the noise by simulating the reverse steps. This way, it will gradually improve the quality of the generated image following a specific dataset style from any input! This is why you don’t need any drawing skills anymore! Since it generates an image from noise, it has no idea and doesn’t need to know the initial input before applying the noise. This is a big difference and a huge advantage compared to other generative networks like conditional GANs. Where you train a model to go from one style to another with these image pairs coming from two different but related datasets.
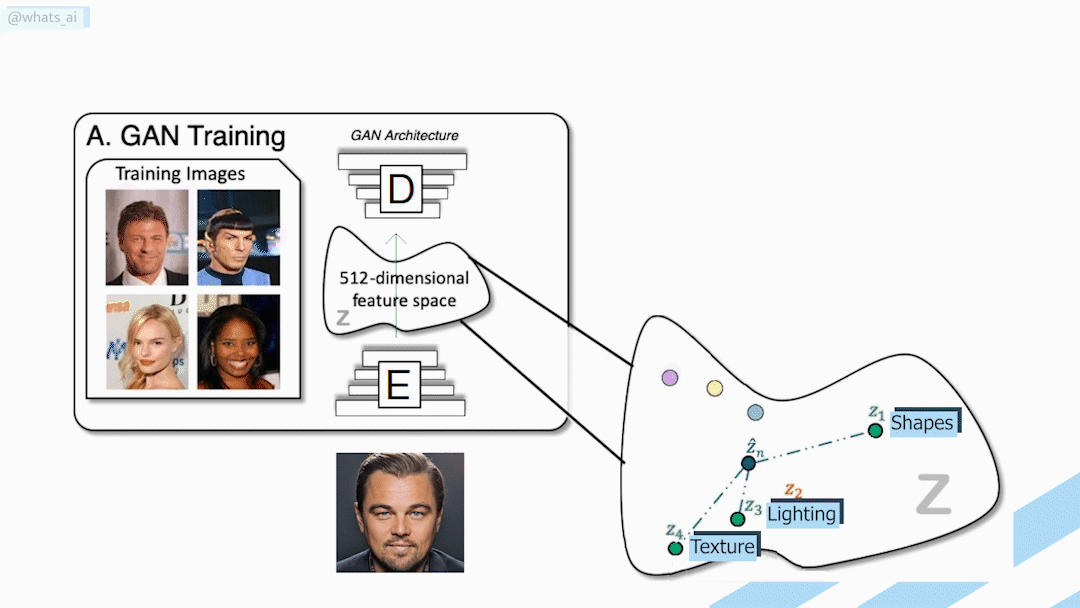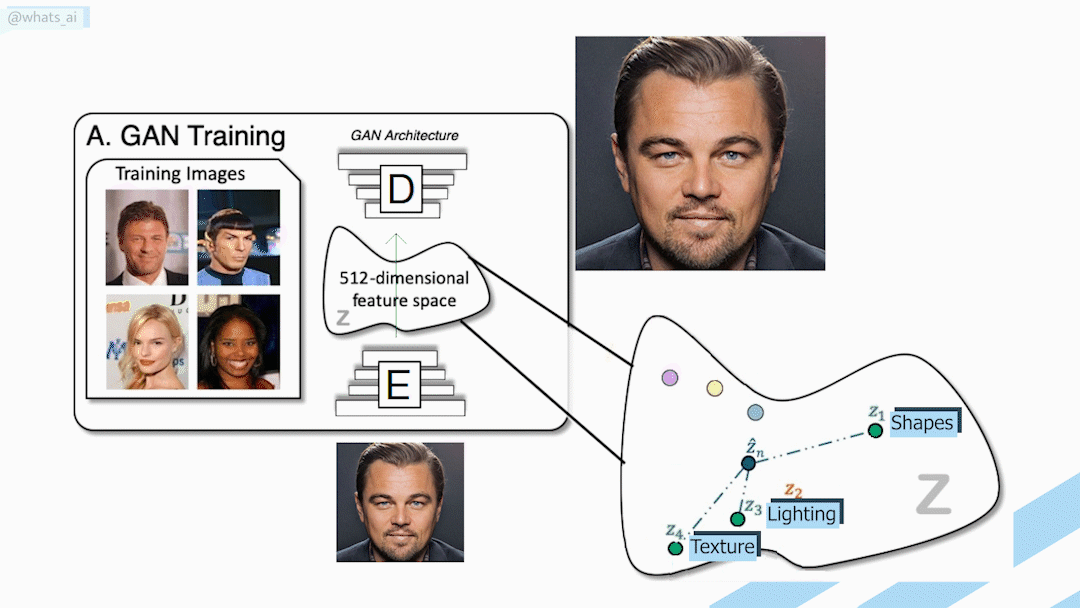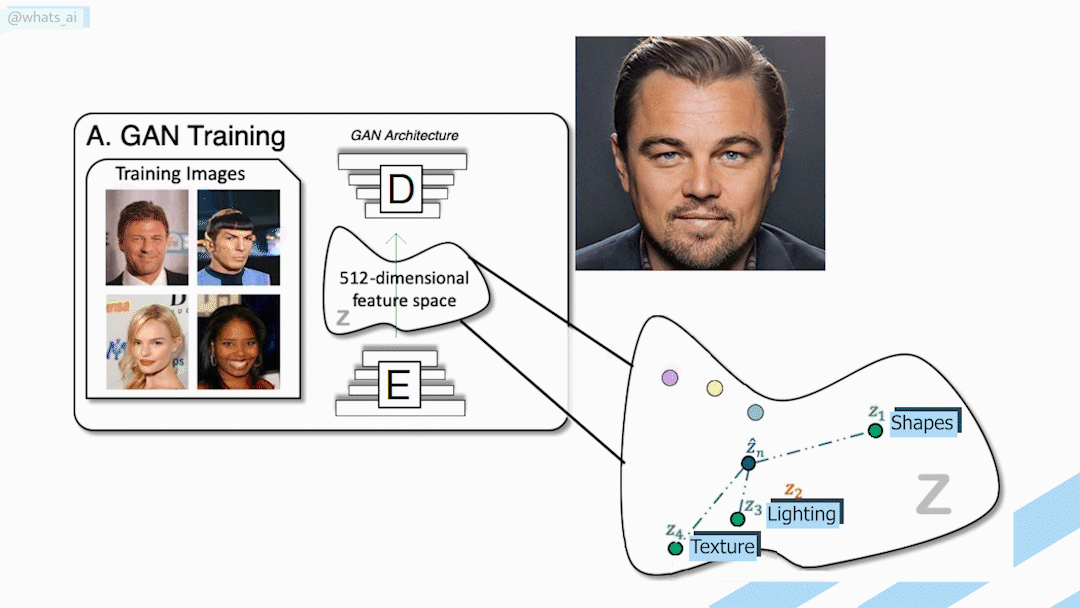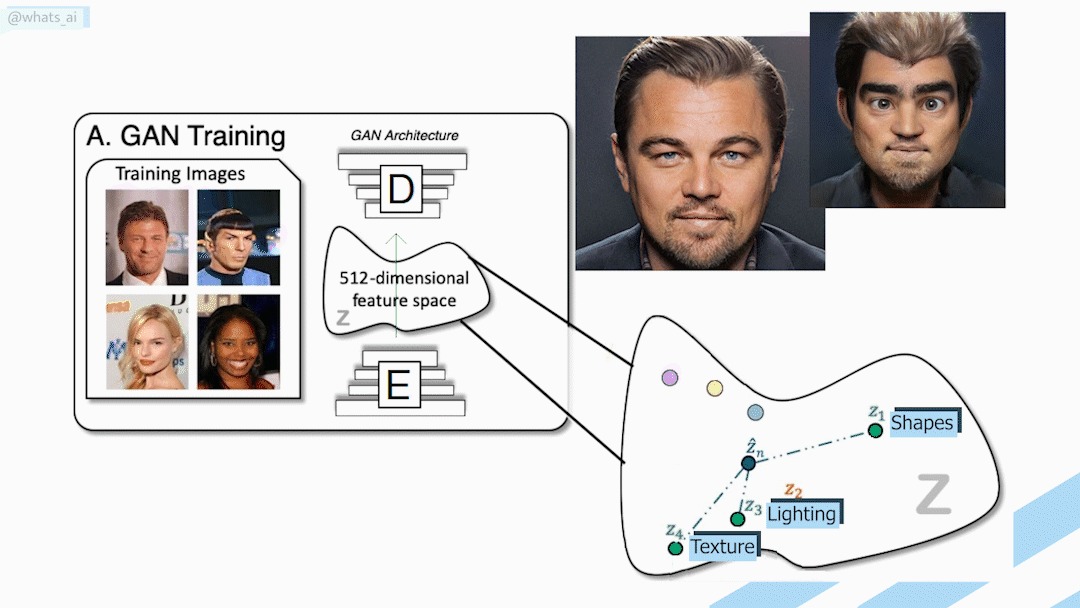
GANs generation process. Needing two datasets: the real faces and the cartoon style
This model called SDEdits uses Stochastic Differential Equations or SDEs, which means that by injecting Gaussian noise, they transform any complex data distribution into a known prior distribution. This known distribution is seen during training, and this is on what the model is trained on to reconstruct the image. So the model learns how to transform this Gaussian noise into a less noisy image and repeats it until we have an image following the wanted style. This method works with whatever type of input because if you add enough noise to it, the image will become so noisy that it joins the known distribution.

SDEdit perturbations (noise addition). SDEdit, Chenlin Meng et al., 2021
Then, the model can take this known input and do the reverse steps, denoising the image based on what it was trained on. Indeed, just like GANs, we need a target dataset, which is the kind of data or images we want to generate. For example, to generate realistic faces, we need a dataset full of realistic faces. Then, we add noise to these face images and teach the model to denoise them iteratively. And this is the beauty of this model because once it has learned how to denoise an image, we can pretty much do anything to the image before adding noise to it, like adding strokes, since they are blended within the expected image distribution from the noise we are adding. Typically, editing an image based on such strokes is a challenging task for a GAN architecture since these strokes are extremely different from the image and from what the model has seen during training. A GAN architecture would need two datasets to fix this issue, the target dataset, which would be the one we try to imitate, and a source dataset, which is the images with a stroke that we are trying to edit.

The complexity problem for data with conditional GANs
These are called paired datasets because we need each image to come in pairs in both datasets to train our model on. We also need to define a proper loss function to train it, making the image synthesis process very expensive and time-consuming.
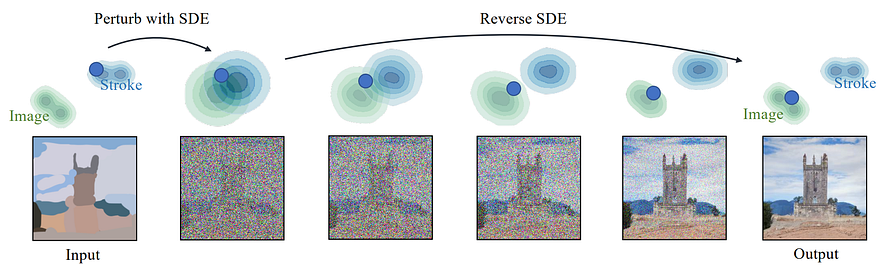
SDEdit perturbations (noise addition) and reverse (noise suppression) process. Image from SDEdit, Chenlin Meng et al., 2021
In our case, with SDEdits we do not need any paired data since the stroke and the image styles are merged because of this noise. This makes the new noisy image part of the known data for the model, which uses it to generate a new image very similar to the training dataset but taking the new structure into account. In other words, it can easily take any edited image as input, blurs it enough, but not too much to keep global semantics and structure detail and denoise it to produce a new image that magically takes your edits into account. And the model wasn’t even trained with stroke or edit examples, only with the original face images! Of course, in the case of a simple user edit, they carefully designed the architecture to only generate the edited part and not re-create the whole picture.
This is super cool because it enables applications such as conditional image generation, stroke-based image synthesis and editing, image inpainting, colorization, and other inverse problems, to be solved using a single unconditional model without re-training. Of course, this will still work for only one generation style, which will be the dataset it was trained on. However, it is still a big advantage as you only need one dataset instead of multiple related datasets with a GAN-based image inpainting network, as we discussed.

SDEdit examples. Image from SDEdit, Chenlin Meng et al., 2021
The only downside may be the time needed to generate the new image, as this iterative process takes much more time than a single pass through a more traditional GAN-based generative model. Still, I’d rather wait a couple of seconds to have great results for an image than having a blurry fail in real-time. You can try it yourself with the code they made publicly available or using the demo on their website, both are linked in the references.

Let me know what you think of this model. I’m excited to see what will happen with this SDE-based method in a couple of months or even less! As you know, this was just an overview of this amazing new technique. I strongly invite you to read their paper for a better understanding of SDEdit, linked below.
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References:
►Read the full article: /image-synthesis-from-sketches/
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
►SDEdit, Chenlin Meng et al., 2021, https://arxiv.org/pdf/2108.01073.pdf
►Project link: https://chenlin9.github.io/SDEdit/
►Code: https://github.com/ermongroup/SDEdit
►Demo: https://colab.research.google.com/drive/1KkLS53PndXKQpPlS1iK-k1nRQYmlb4aO?usp=sharing
FAQ
What does SDEdit do?
SDEdit turns a sketch or rough image into a realistic result using a pretrained diffusion model.
Why add noise to the user's input?
Noise moves the rough input toward a representation the pretrained model knows how to denoise realistically.
How does SDEdit preserve the original idea?
The noise level leaves enough structure from the input to guide composition while allowing visual refinement.
Does SDEdit require paired sketch-image training data?
No. It uses an existing generative prior instead of training on matching sketches and finished images.
What tradeoff does the noise level control?
Too little noise preserves artifacts, while too much can erase the composition the user wanted.