

The short version
MusicLM is a 2023 Google Research system that generates music from text by translating the description through several learned token representations. MuLan aligns text and audio, an autoregressive model produces semantic tokens, and SoundStream supplies acoustic tokens that can be decoded into sound. The work also released MusicCaps, 5,500 human-written music-text pairs, and should be read as an early text-to-music research snapshot.
We recently covered a model able to imitate someone’s voice called VALL-E. Let’s jump a step further in the creative direction with this new AI called MusicLM. MusicLM allows you to generate music from a text description, which I invite you to listen to on their website or in my video…
Assuming you’ve taken the time to listen to some of the songs… How cool is that? These pieces you’ve heard were completely AI-generated!
Even more interesting than listening to a few more examples is how it works; let’s dive into what this AI is!
So how did they do that?
Well, as with most recent models, it was by taking the best of multiple approaches.
More specifically, they mention that their approach is very similar to DALLE 2, which I already covered on my channel, but with a difference that it generates music rather than images and uses Transformer-based models instead of diffusion-based ones.
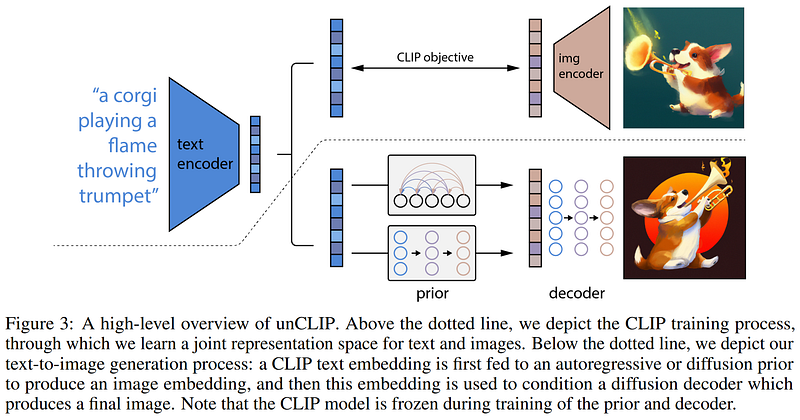
DALLE-2 architecture. Image from the DALLE-2 paper.
So let’s get back a little…
What do we have to do here?
1. We have to process text in a way the machine can understand it.
2. We have to understand it.
3. We have to generate a new and unseen music track that would relatively mean the same thing as this text input.
These are basically the same steps as with DALLE and other image generation models: we take some text, understand it and then generate an image that represents this text in another modality humans understand.
Let’s go into these steps one by one…
First, we need to process text in a way the machine can understand it.
How do we do that?
Well, we do that by taking a model trained with lots of text and sound pairs that learns to represent both similarly in its encoded space. It basically learns to transform both into similar representations in its own language. This is the same as using with generative image models if you’ve seen my videos on the topic, where we want our text to be the same as an image representing it. This will be done thanks to a lengthy training process with a lot of examples. In our case, this specific model is called MuLan:
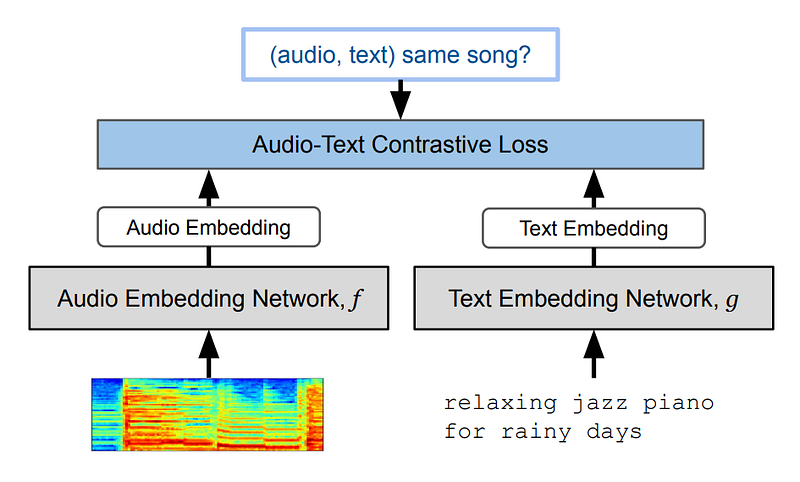
Image from the MuLan paper.
Then, as I said, we need to understand this text. This is done in a sequential manner by learning transformations to go from our text to audio representation.
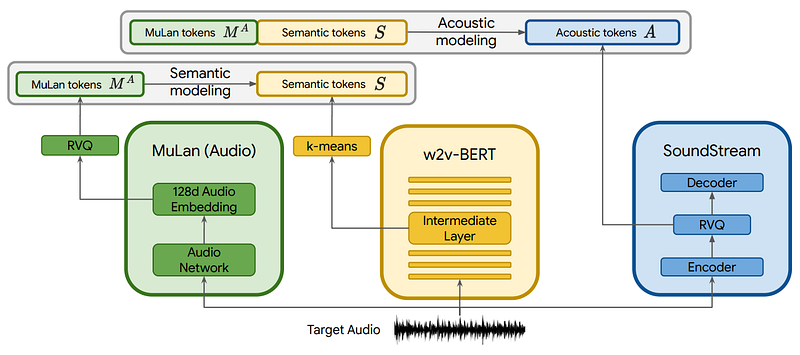
Training architecture overview with our three models. Image from the paper.
First, we will use a model that we trained on our music examples to learn a way to map our MuLan encodings, which we call tokens, into semantic tokens. This will simply give more information to the tokens for our audio transformation, which we now do.
We use everything we have: our text-transformed MuLan tokens and our new semantic tokens based on learned transformations and use a third model, called SoundStream, to create acoustic tokens, ready to be interpreted by the model and generate our sound.
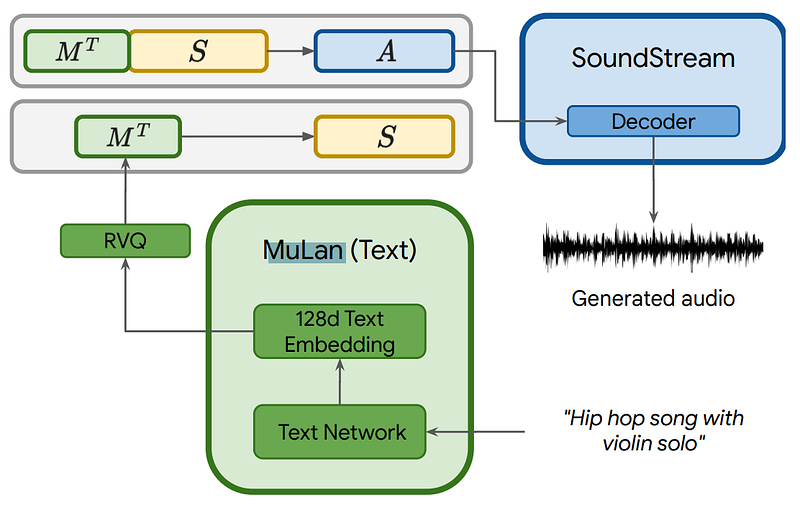
Model overview for inference. Image from the paper.
When the training is done, we simply use our trained models to take the text, transform it into a meaningful representation for the machine, apply our learned transformations, and use our last sub-model to generate the desired song.
And voilà!
This is how Google Research was able to create a model generating music with such great results from simple text descriptions!
But don’t take my word for it; go listen to some examples on their website!
They also release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts, which will surely help improve future approaches.
Of course, this was just an overview of this new MusicLM model. I invite you to read their paper for more information.
I hope you’ve enjoyed this article, and I will see you next week with another amazing paper!
References
►Agostinelli et al., 2023: MusicLM, https://arxiv.org/pdf/2301.11325.pdf
►Listen to more results: https://google-research.github.io/seanet/musiclm/examples/
►My Newsletter: /newsletter/
►Support me on Patreon: https://www.patreon.com/whatsai
►Join Our Discord community, Learn AI Together: https://discord.gg/learnaitogether
FAQ
What does MusicLM generate?
MusicLM creates music from a natural-language description of style, instruments, mood, or other musical characteristics.
How is text-to-music different from text-to-speech?
Music generation must model long-range rhythm, harmony, instrumentation, and structure rather than spoken language content.
Can the prompt control the generated sound?
The description guides broad attributes, although the model may not follow every requested musical detail precisely.
How is MusicLM different from a voice-cloning model such as VALL-E?
MusicLM generates musical audio, while VALL-E focuses on synthesizing speech in a particular voice.
What concerns come with generated music?
Training rights, stylistic imitation, attribution, artist consent, and commercial use require careful policy and legal review.