Your Personal Photoshop Expert with AI!
This AI can reconstruct, enhance and edit your images!


Watch the video
This new model by Google Research and Tel-Aviv University is incredible. You can see it as a very, very powerful deepfake that can do anything. Take a hundred pictures of any person and you have its persona encoded to fix, edit or create any realistic picture you want. This is both amazing and scary if you ask me, especially when you look at the results. Just take a minute to admire them in the video…
The model simply uses a pertained StyleGAN architecture, which I covered in numerous videos so I won’t enter into the detail of this network. Quickly, StyleGAN takes an image, encodes it using convolutional neural networks, and is trained to re-generate the same image. If this sounds like another language to you, just take two minutes to watch this video I made covering StyleGAN.
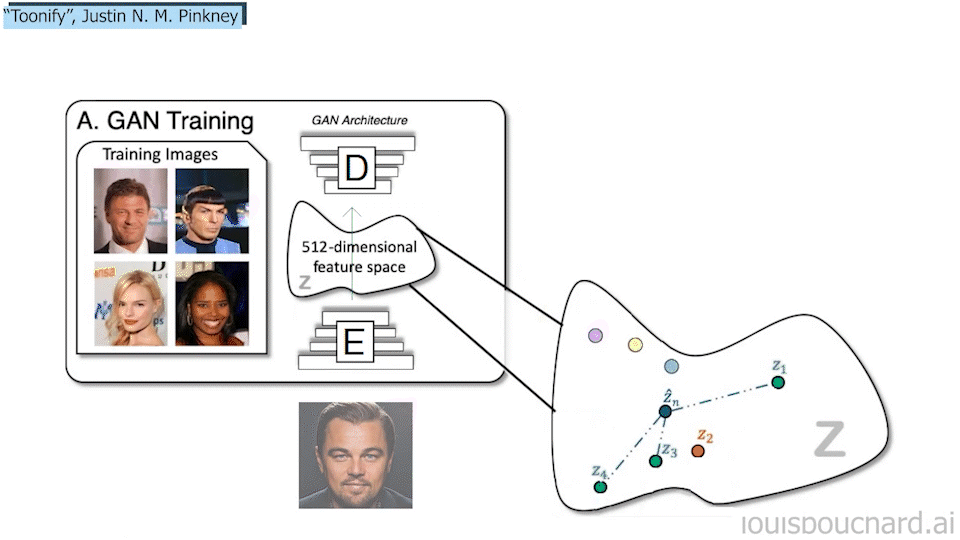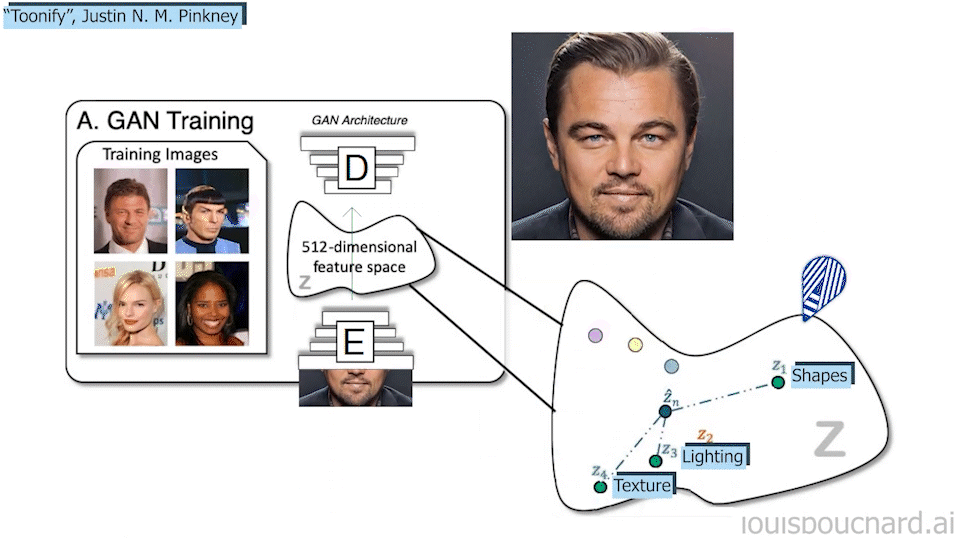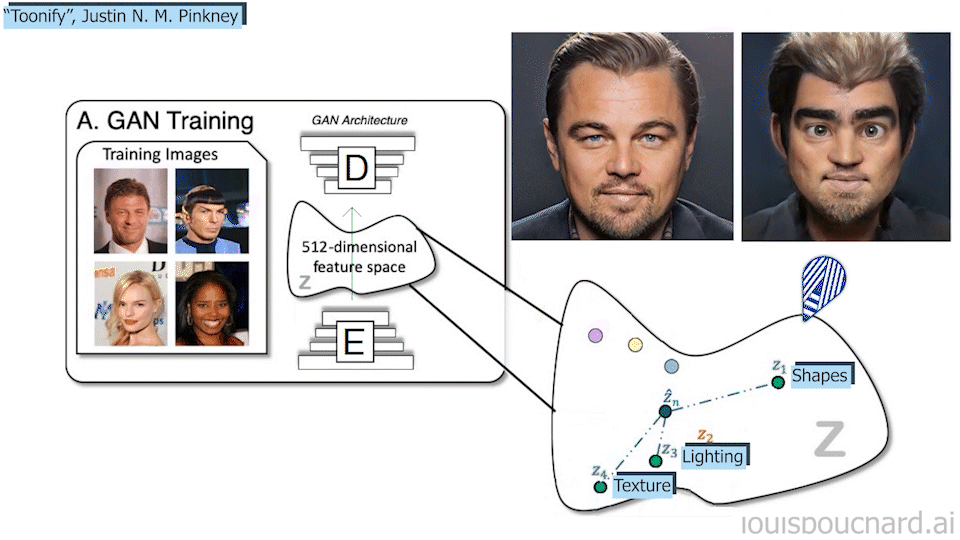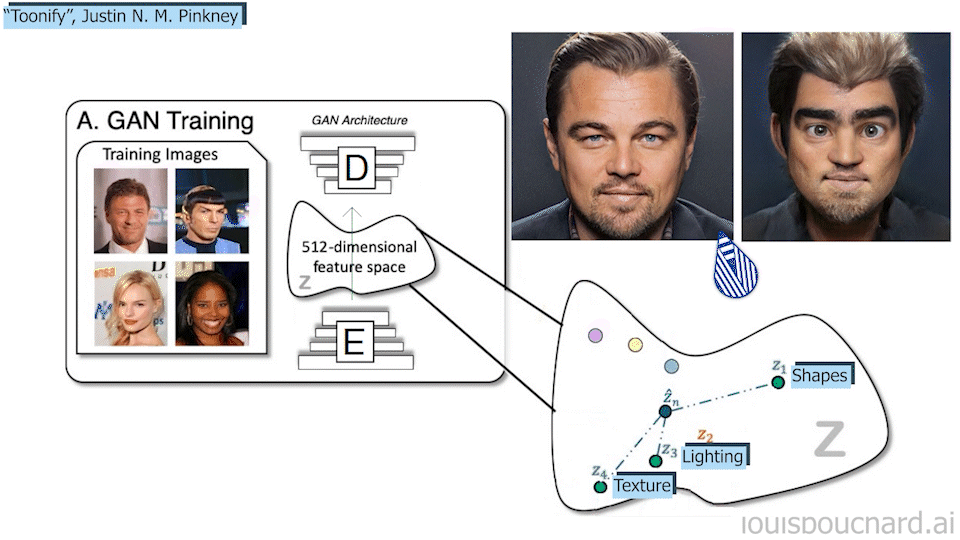
Then, when you have it well trained with a big dataset of many people, you can teach it to transform the image directly from the encoded space, as I explained in my videos. So you don’t need to feed it images anymore, you can simply play with what we call the generator.
This means you can teach it to change the whole picture like a style transfer application where you would, for example, take a realistic picture and encode it, or start right from the encoding, and transform it into an anime-like digital image. Trained and manipulated properly, you can also change only some local features like the color of the hair or any other edits to make you look your best.
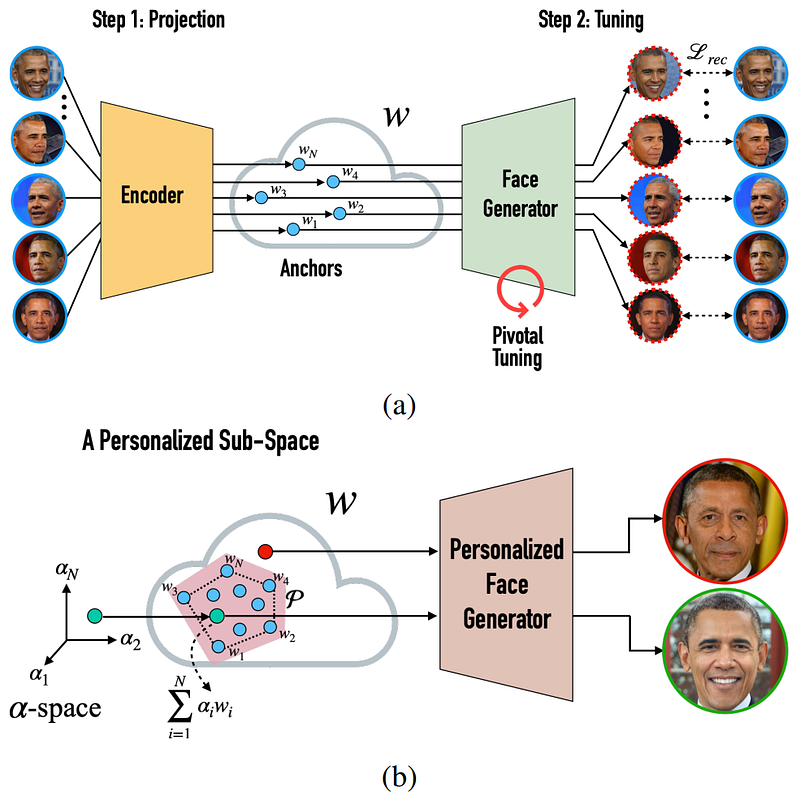
So this new model called MyStyle uses this StyleGAN base model and modifies it to achieve a style transfer task and any task that can be associated with your face. As I said, it literally learns how you look and can do pretty much anything; inpainting, super-resolution, or editing.

Image inpainting is where you’d have some object in the shot covering your face and you’d remove this object from the picture and make your face reappear. Just like if you enabled transparency in a video game to see through the walls.

Image super-resolution is an incredibly challenging task when trying to generalize to many different faces but much easier when you focus on one person. Here, the goal is to take a very low definition image and upscale it to a high-resolution one. So you basically have this, a blurry image of yourself, and you try to make it look like the image on the right.
You can see how these two applications are quite challenging for a machine as it needs to know the person in order to fill in big gaps or add pixels to make the face look sharper. The model basically has to be both a very close friend of yours and a great artist at the same time as it needs to know what your face looks like from any angle, as well as be able to draw it realistically. While I will always do the most I can to be the best friend possible, forget about me drawing an accurate version of your face if you want good results. This is just on another level.
So taking this StyleGAN basis trained with a huge general dataset of thousands of people, and a hundred pictures of yourself, MyStyle will learn an encoded space unique to your face (step 1 in the model overview above). It will basically find you in the encoded representation of all faces and be re-trained to push the model to focus on your different features.
Then, you will be able to feed it incomplete or failed pictures of yourself and ask it to fix it for you (step 2 in the model overview above). How cool is that? It requires quite a lot of images of yourself, but 100 pictures just mean a big day outside with a friend and your phones to have much better results than the general models that try to generalize to everyone. It is also much cheaper than hiring a professional on Photoshop and asking to edit all your future pictures.
Still, you can see how this kind of model can be dangerous for famous people or those with a lot of Instagram pictures. Someone could use them to train a model and basically create super-realistic pictures of yourself in compromising situations. This is why I often say that we can’t trust what we see anymore, especially on the internet. Let’s not think about all the possible issues when it will also be in the real world with augmented reality glasses.

Nonetheless, the results are fantastic and much better than what we’ve seen before considering it only requires a hundred pictures of yourself instead of hours of video shooting for older deep fakes and has much fewer artifacts than those requiring fewer images performing only a single task.
And voilà! This is how MyStyle, a new model from Google Research and Tel-Aviv University is able to perform image inpainting, image super-resolution,
and image editing using a single architecture and training scheme compared to other approaches as it focuses on the person instead of the task itself, which makes it much more accurate, realistic, and generalizable.
I hope you enjoyed the article! Let me know what you think of this shorter and simpler format if you like it or not. Of course, this was just a quick overview of this new paper and I strongly recommend reading the paper linked below for a better understanding of their training scheme and the model.
I will see you next week with another amazing paper!
Louis
References
►Nitzan, Y., Aberman, K., He, Q., Liba, O., Yarom, M., Gandelsman, Y., Mosseri, I., Pritch, Y. and Cohen-Or, D., 2022. MyStyle: A Personalized Generative Prior. arXiv preprint arXiv:2203.17272.
►Project link: https://mystyle-personalized-prior.github.io/
►Code (coming soon): https://mystyle-personalized-prior.github.io/
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/