OpenAI's new model DALL·E 2 is amazing!
An amazing new model by OpenAI capable of generating and inpainting images from a text input with incredible results!


Watch the video
Last year I shared DALL·E, an amazing model by OpenAI capable of generating images from a text input with incredible results. Now is time for his big brother, DALL·E 2. And you won’t believe the progress in a single year! DALL·E 2 is not only better at generating photorealistic images from text. The results are four times the resolution!


As if it wasn’t already impressive enough, the recent model learned a new skill; image inpainting.
DALL·E could generate images from text inputs.
DALL·E 2 can do it better, but it doesn’t stop there. It can also edit those images and make them look even better! Or simply add a feature you want like some flamingos in the background.
This is what image inpainting is. We take the part of an image and replace it with something else following the style and reflections in the image keeping realism. Of course, it doesn’t only replace the part of the image at random, this would be too easy for OpenAI. This inpainting process is text-guided, which means you can tell it to add a flamingo here, or there.



Let’s dive into how DALL·E 2 can not only generate images from text but is also capable of editing them. Indeed, this new inpainting skill the network has learned is due to its better understanding of concepts and the images themselves, locally and globally.
What I mean by locally and globally is that DALL·E 2 has a deeper understanding of why the pixels next to each other have these colors as it understands the objects in the scene and their interrelations with each other. This way, it will be able to understand that this water has reflection and the object on the right should be also reflected there.

It also understands the global scene; what’s happening, just like if you were to describe what was going on when the person took the photo.

Here you’d say that this photo does not exist. Obviously, or else I’m definitely down to try that. If we forget that this is impossible, you’d say that the astronaut is riding a horse in space. So if I were to ask you to draw the same scene but on a planet rather than in free space, you’d be able to picture something like that since you understand that the horse and astronaut are the objects of interest to keep in the picture.

This seems obvious, but it’s extremely complex for a machine that only sees pixels of colors, which is why DALL·E 2 is so impressive to me.
But how exactly does the model understand the text we send it and can generate an image out of it? Well, it is pretty similar to the first model that I covered on the channel.
It starts by using the CLIP model by OpenAI to encode both a text and an image into the same domain; a condensed representation called a latent code.
Then, it will take this encoding and use a generator, also called a decoder, to generate a new image that means the same thing as the text since it is from the same latent code. So DALL·E 2 has two steps; CLIP to encode the information and the new decoder model, to take this encoded information and generate an image out of it. These two separated steps are also why we can generate variations of the images. We can simply randomly change the encoded information just a little, making it move a tiny bit in the latent space, and it will still represent the same sentence while having all different values creating a different image representing the same text.
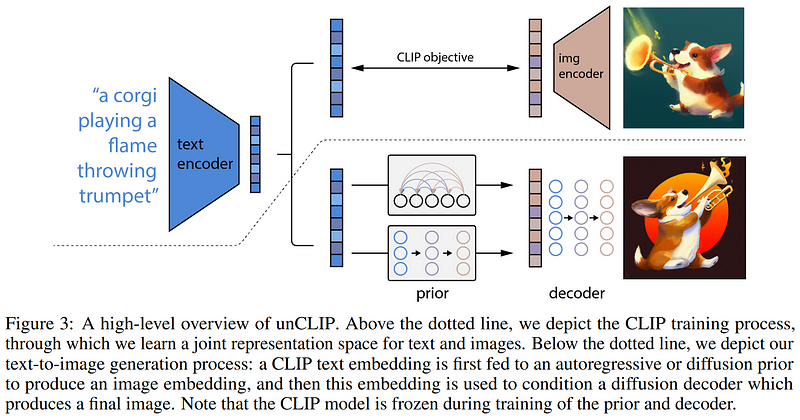
As we see here, it initially takes a text input and encodes it.
What we see above is the first step of the training process where we also feed it an image and encode it using CLIP so that the images and texts are encoded similarly following the CLIP objective. Then, for generating a new image, we switch to the section below where we use the text encoding guided by CLIP to transform it into an image-ready encoding. This transformation is done using a diffusion prior, which we will cover shortly as it is very similar to the diffusion model used for the final step. Finally, we use our newly created image encoding and decode it into a new image using a diffusion decoder!
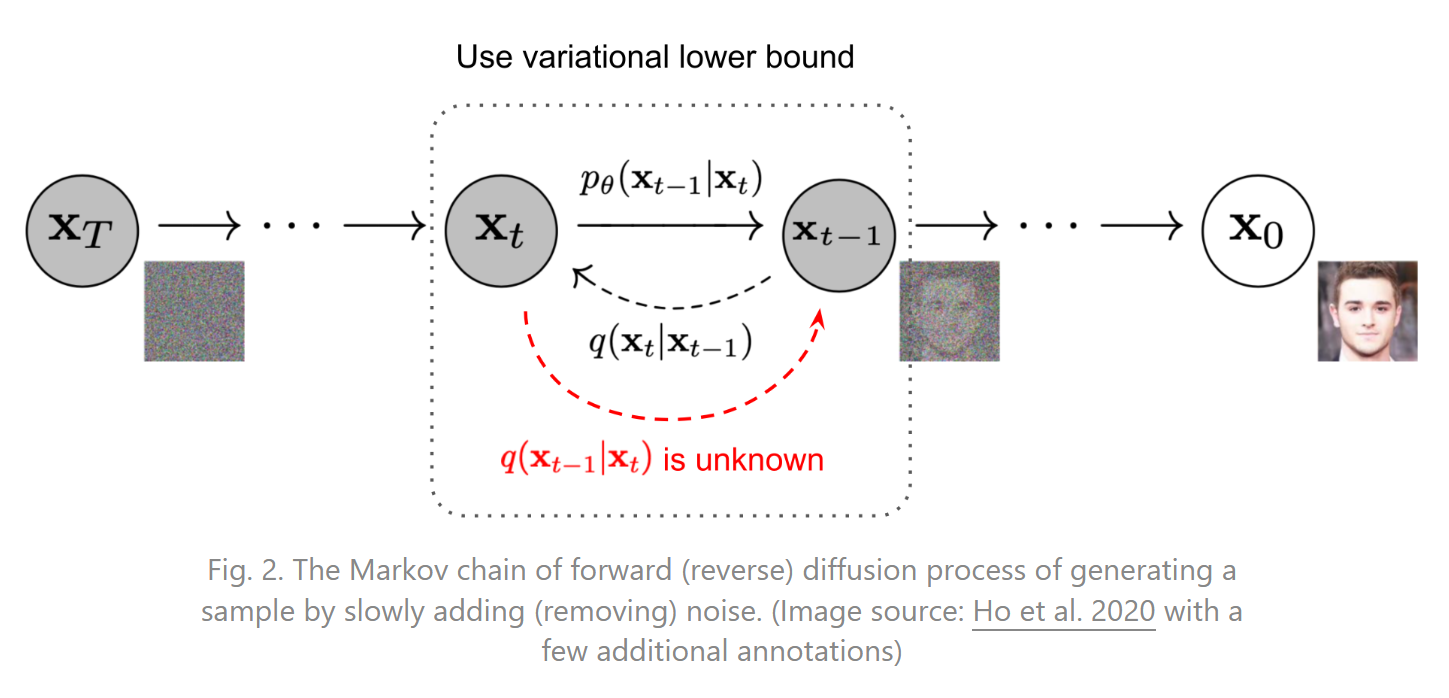
A diffusion model is a kind of model that starts with random noise and learns how to iteratively change this noise to get back to an image. It learns that by doing the opposite. During training, we will feed it images and apply random Gaussian noise on the image iteratively until we can’t see anything other than noise. Then, we simply reverse the model to generate images from noise. If you’d like more detail about this kind of network, which are really cool, I invite you to watch this video I made about them.
And voilà! This is how DALL·E 2 generates such high-quality images following text! It’s super impressive and tells us that the model does understand the text.
But does it deeply understand what it created? Well, it sure looks like it. It’s the capability of inpainting images that makes us believe that it does understand the pictures pretty well. But why is that so, how can it link a text input to an image, and understand the image enough to replace only some parts of it without affecting the realism? This is all because of CLIP as it links a text input to an image. If we encode back our newly generated image and use a different text input to guide another generation, we can generate this second version of the image that will replace only the wanted region in our first generation. And you will end up with this picture:


Unfortunately, DALL·E 2’s code isn’t publicly available and is not in their API yet. The reason for that, as per OpenAI, is to study the risks and limitations of such a powerful model. They actually discuss these potential risks and the reason for this privacy in their paper and in a great repository I linked in the references below if you are interested. They also opened an Instagram account to share more results if you’d like to see that, it is also linked below.
I loved DALL·E, and this one is even cooler. Of course, this was just an overview of how DALL·E 2 works and I strongly invite reading their great paper linked below for more detail on their implementation of the model.
I hope you enjoyed the article as much as I enjoyed writing it, and if you did, please consider supporting my work on YouTube by subscribing to the channel and commenting on what you think of this summary. I’d love to read what you think!
References
►Read the full article: https://www.louisbouchard.ai/dalle-2/
►A. Ramesh et al., 2022, DALL-E 2 paper: https://cdn.openai.com/papers/dall-e-2.pdf
►OpenAI’s blog post: https://openai.com/dall-e-2
►Risks and limitations: https://github.com/openai/dalle-2-preview/blob/main/system-card.md
►OpenAI Dalle’s instagram page: https://www.instagram.com/openaidalle/
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/