

The short version
Panoptic scene graph generation builds a structured description of an image by segmenting both objects and background regions, then predicting the relationships among them. In this 2022 paper overview, a Panoptic FPN first produces masks and features, and a relation model turns those features into graph triplets. The dataset, baseline, code, and demos made PSG a research task people could test, not a solved form of scene understanding.
Watch the video
You can use AI to identify what’s in an image, like finding out whether there’s a cat or not. If there’s one, you can use another AI to find where it is in the image. And you can find it very precisely. These tasks are called image classification, object detection, and finally, instance segmentation.

Then you can build cool applications to extract your cat from an image and put it into a fun gift card or a meme. But what if you want an application that understands the scene and image? Not only being able to identify whether there’s an object and where it is, but what’s happening. You don’t want to identify if there’s a customer or not in a shop, but you might want to identify if the customer in question is stealing you. Whether using such surveillance is ethically correct or not is a whole other question you need to consider.
Still, suppose we focus on finding out what’s happening in a scene or a particular picture. In that case, you’d want to use a task called scene graph generation (figure below, left) where objects are detected using bounding boxes, as shown previously with object detection, which is then used to create a graph with each object’s relationship to each other object. It will basically try to understand what’s happening from all the principal objects of the scene. It works quite well and finds out these main characteristics of the image, but there’s a big problem. It relies on the bounding box accuracies and completely disregards the background, which is often crucial in understanding what’s happening or at least giving a more realistic summary.
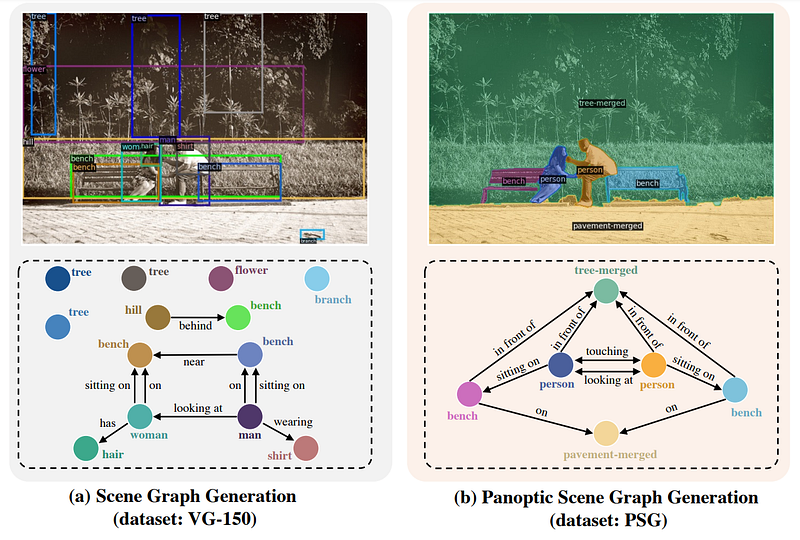
“Fig. 1: Scene graph generation (a. SGG task) vs. panoptic scene graph generation (b. PSG task). The existing SGG task in (a) uses bounding box-based labels, which are often inaccurate — pixels covered by a bounding box do not necessarily belong to the annotated class — and cannot fully capture the background information. In contrast, the proposed PSG task in (b) presents a more comprehensive and clean scene graph representation, with more accurate localization of objects and including relationships with the background (known as stuff), i.e., the trees and pavement.” Image by Yang et al., 2022: PSG.
Instead, you might want to use this new task called panoptic scene graph generation, or PSG (image above, right). PSG is a new problem task aiming to generate a more comprehensive graph representation of an image or scene based on panoptic segmentation rather than bounding boxes. Something much more precise, taking into account all pixels of an image, as we saw.
And the creators of this task didn’t only invent it but they also created a dataset as well as a baseline model to test your results against, which is really cool. This task has a lot of potential as understanding what is happening in an image is incredibly useful and complex for machines even though humans do it automatically. It brings some sort of needed intelligence to the machines, making the difference between being a cool funny app like Snapchat to a product you’d use to save time or complete a need, like understanding when your cat wants to play and using a robot to play with it automatically so it isn’t bored all the time.

Panoptic Scene Graph Generation. Clip by Yang et al., 2022: PSG.
Understanding a scene is really cool, but how can a machine do that?
Well, you need two things: a dataset and a powerful model. We know that we have the dataset since they built it for us. Now the second thing: how to learn from this dataset? Or, in other words, how to build this AI model, and what should it do? There are multiple ways to approach this problem, and I invite you to read their paper to find out more. Here’s one way to do it.
But first, give me a few seconds to be my own sponsor and talk about our community! Since you are reading this article, I know you’ll love it as it was basically created for you.
Of course, we have the YouTube community, which you should definitely join. For instance, I’d love to know if you think this task is interesting or not to the AI community.
It is a place to connect with fellow AI enthusiasts from any skill level, find people to learn with, find people to work with, ask your questions or even find interesting job offers. We are organizing a lot of very cool events and Q&As, like the one we are currently running with the MineRL organizers from Deepmind and OpenAI. The link is in the description below and I’d love to see you join us and exchange there!
What is Panoptic Scene Graph Generation?
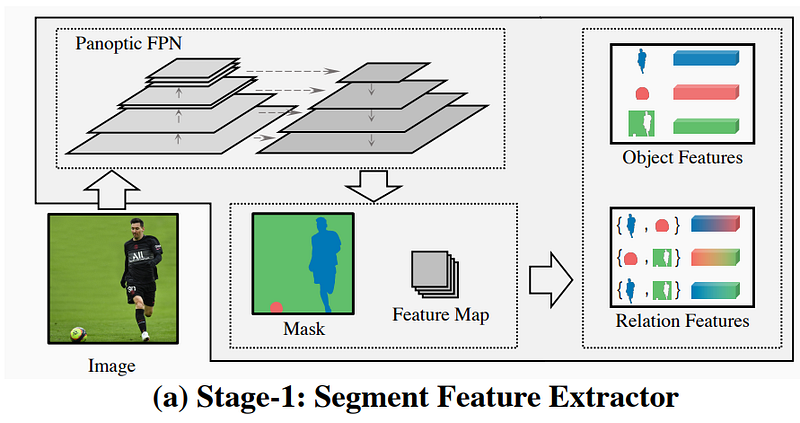
“In stage one, for each thing/stuff object, Panoptic FPN [32] produces a segmentation mask with its tightest bounding box to crop out the object feature. The union of relevant objects can produce relation features.” Image by Yang et al., 2022: PSG.
As we said, the model needs to find the class of each pixel of the image. Meaning that it has to identify every pixel of the image. The first stage (image above) of the model will be responsible for this. It will be a model, called Panoptic FPN, already trained to classify each pixel. Such a model is already available online and quite powerful. It will take an image and return what we call a mask with each pixel matched to an existing object like a ball, human, or grass in this case. You now have the segmentation, and you know what’s in the image and where. If you are not familiar with how such a model works, I invite you to read one of the articles I made covering similar approaches like this one. The next step is to find out what’s happening with those objects.
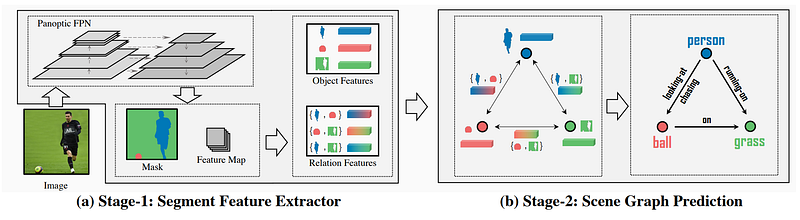
“Fig. 3: Two-stage PSG baselines using Panoptic FPN. a) In stage one, for each thing/stuff object, Panoptic FPN [32] produces a segmentation mask with its tightest bounding box to crop out the object feature. The union of relevant objects can produce relation features. b) In the second stage, the extracted object and relation features are fed into by any existing SGG relation model to predict the relation triplets.” Image by Yang et al., 2022: PSG.
Here, you already know it’s a man playing soccer on a field, but the machine actually has no idea. The only thing it knows is that there is a man, a ball, and a field with a lot of confidence, but it doesn’t understand anything and cannot connect the dots as we do with ease. We need a second model (image above, right) trained just to take those objects and figure out why they are in the same picture. This is the scene graph generation step where a model will learn how to match a dictionary of words and concepts covering multiple possible object relations to objects in the scene using the information extracted from the first stage, learning how to structure the objects with each other object.
And voilà!
You end up with a clear graph that you can use to build sentences and paragraphs covering what’s happening in your image. You can now use this approach in your next application and give a few IQ points to your approach, getting it closer to something intelligent!
If you’d like to learn more about this new task, I strongly invite you to read the paper linked below.
Thank you for reading until the end, and I will see you next week with another amazing paper, and congrats to the authors for being accepted to ECCV 2022, which I will attend as well!
References
►Yang, J., Ang, Y.Z., Guo, Z., Zhou, K., Zhang, W. and Liu, Z., 2022. Panoptic Scene Graph Generation. arXiv preprint arXiv:2207.11247.
►Code: https://github.com/Jingkang50/OpenPSG
►Project page (PSG dataset): https://psgdataset.org/
►Try it: https://replicate.com/cjwbw/openpsg, https://huggingface.co/spaces/ECCV2022/PSG
FAQ
What is panoptic scene graph generation?
It segments every visible region and predicts semantic relationships among the objects in one unified scene graph.
How is this harder than object detection?
Detection finds objects, while PSG must also segment background regions and infer how all elements relate.
What does a scene graph contain?
It represents objects or regions as nodes and relationships such as holding, behind, or next to as edges.
Why does PSG need a specialized dataset?
Training requires images labeled with both pixel masks and many relationship annotations.
Where could scene graphs be useful?
They can support visual question answering, robotics, accessibility, search, and systems requiring structured scene understanding.