How AI Understands Words
Text Embedding Explained


Watch the video
Large language models.
You must’ve heard these words before. They represent a specific type of machine learning-based algorithms that understand and can generate language, a field often called natural language processing or NLP.
You’ve certainly heard of the most known and powerful language model: GPT-3. GPT-3, as I’ve described in the video covering it is able to take language, understand it and generate language in return. But be careful here; it doesn’t really understand it. In fact, it’s far from understanding. GPT-3 and other language-based models merely use what we call dictionaries of words to represent them as numbers, remember their positions in the sentence, and that’s it.
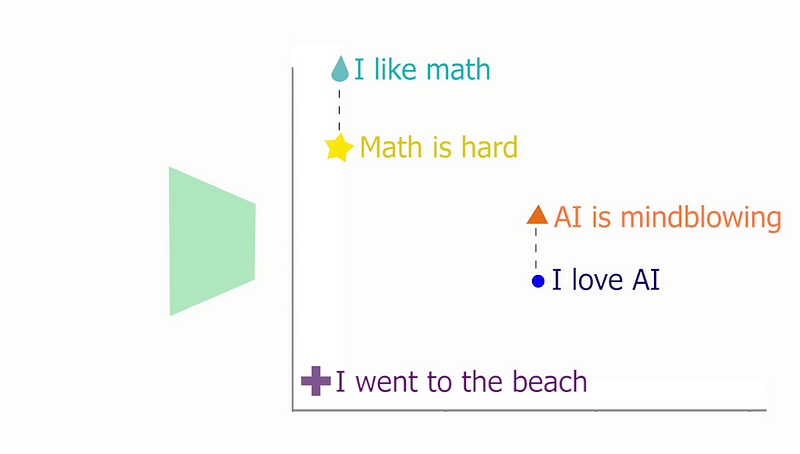
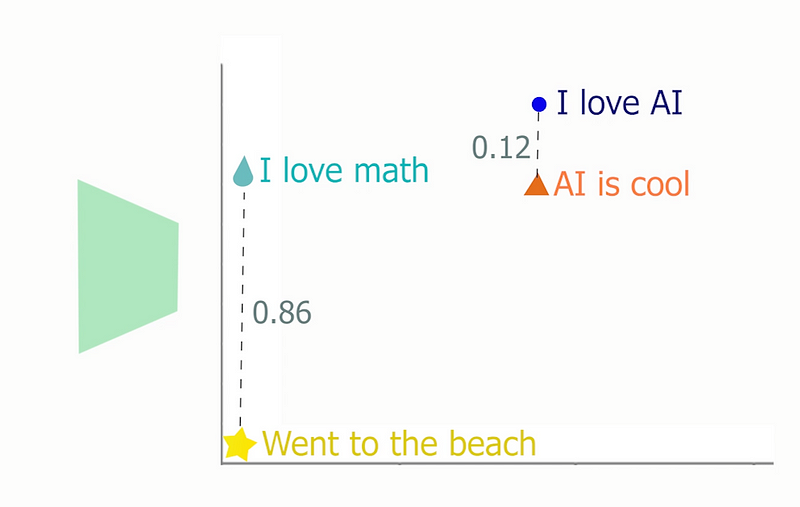
Using a few numbers and positional numbers, called embeddings, they are able to re-group similar sentences, which also means that they are able to kind of understand sentences by comparing them to known sentences, e.g., our dataset. It is the same process for image synthesis models that take your sentence to generate an image, they do not really understand it, but they can compare it to similar images, producing some sort of understanding of the concepts in your sentence.
In this article, we will give a look at what those powerful machine learning models see instead of words, called word embeddings, and how to produce them with an example provided by Cohere.
We’ve talked about embeddings and GPT-3, but what’s the link between the two? Embeddings are what is seen by the models and how they process the words we know. And why use embeddings? Well, because, as of now, machines cannot process words, and we need numbers in order to train those large models. Thanks to a carefully built dataset, we can use mathematics to measure the distance between embeddings and correct our network based on this distance, iteratively getting our predictions closer to the real meaning and improving the results.

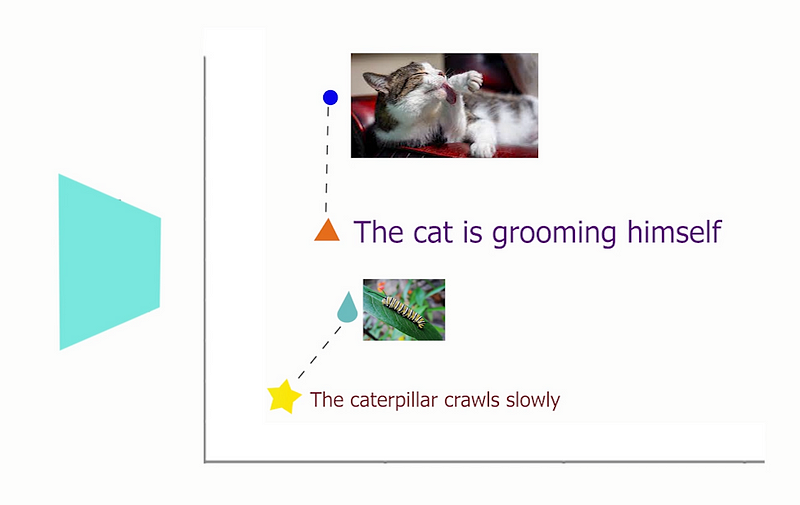
Embeddings are also what the models like CLIP, Stable Diffusion, or DALLE use to understand sentences and generate images. This is done by comparing both images and text in the same embedding space, meaning that the model does not understand either text or images, but it can understand if an image is similar to a specific text or not. So if we find enough image-caption pairs, we can train a huge and powerful model like DALLE to take a sentence, embed it, find its nearest image-clone and generate it in return.
So machine learning with text is all about comparing embeddings, but how do we get those embeddings?
We get it using another model trained to find the best way to generate similar embeddings for similar sentences while keeping the differences in meaning for similar words compared to using a straight 1:1 dictionary. The sentences are usually represented with special tokens marking the beginning and end of our text.

Then, as I said, we have our positional embeddings, which indicate the position of each word relative to each other, often using sinusoidal functions. I linked a great article about this in the references if you’d like to learn more.
Finally, we have our word embeddings. We start with all our words being split into an array, just like a table of words. Starting now, they are no longer words. They just are tokens, or numbers, from the whole English dictionary.
You can see here that all the words now are represented by a number indicating where they are in the dictionary, thus having the same number for the word bank even though their meanings are different in the sentence we have.
Now, we add a little bit of intelligence to that, but not too much. This is done thanks to a model trained to take this new list of numbers and further encode it into another list of numbers that better understand the sentence. For example, it would no longer have the same embedding for the two words “bank” here. This is possible because the model used to do that has been trained on a lot of annotated text data and learned to encode similar-meaning sentences next to each other and opposite sentences far from each other, thus allowing our embeddings to be less biased by our choice of words than the initial simple 1:1 word:indice embedding we initially had.

Here’s what using embeddings looks like in a very short NLP example. There are more links below to learn about embeddings and how to code it yourself.
Here, we will take some hacker news posts and build a model able to retrieve the most similar post of a new input sentence.
To start, we need a dataset. In this case, it is a pre-embedded set of three thousand hacker news posts that have already been embedded into numbers.
Then, we build a memory saving all those embeddings for future comparison. We basically just save these embeddings in an efficient way.
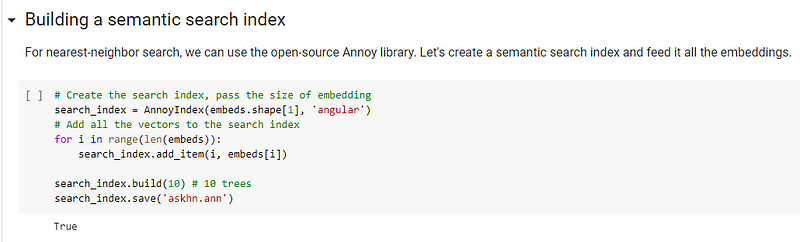
Then, when a new query is done, for example, here asking “What is your most profound life insight?”, you can generate its embedding using the same embedding network. Usually, it is BERT or a version of it, and we compare the distance in the embedding space to all other hacker news posts in our memory. Note that it is really important here to always use the same network, whether for generating your dataset or for querying it. As I said, there is no real intelligence here, nor that it actually understands the words. It just has been trained to embed similar sentences nearby in the embedding space, nothing more.
If you send your sentence to a different network to generate an embedding and compare the embedding to the ones you had from another network, nothing will work.
It would just be like the people that tried to talk to me in Hebrew at ECCV last week. It just wasn’t in an embedding space my brain could understand.
Fortunately for us, our brain can learn to transfer from one embedding space to another, as I can with French and English, but this requires a lot of work and practice, and it is the same for machines.
Anyways, coming back to our problem, we could find the most similar posts. That’s pretty cool, but how could we achieve this? As I mentioned, it is because the network, BERT in this case, learns to create similar embeddings from similar sentences. We can even visualize it in two dimensions like this, where you can see how two similar points represent similar subjects.
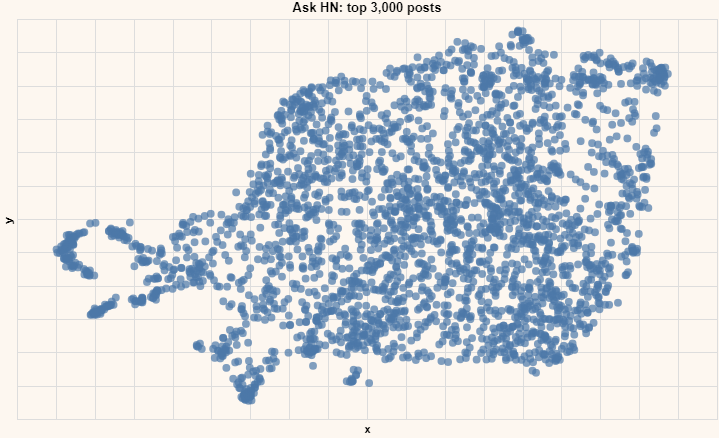
You can do many other things once you have those embeddings, like extracting keywords, performing a semantic search, doing sentiment analysis, or even generating images, as we said and demonstrated in previous videos. I have a lot of videos covering those and listed a few interesting notebooks to learn to play with encodings, thanks to the Cohere team.
Thank you for reading!
Louis
References
►BERT Word Embeddings Tutorial: https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/#why-bert-embeddings
►Cohere’s Notebook from the code example: https://colab.research.google.com/github/cohere-ai/notebooks/blob/main/notebooks/Basic_Semantic_Search.ipynb
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/