

The short version
DragGAN edits a GAN-generated image by letting you drag chosen points to new positions while the model adjusts pose, shape, expression, or surrounding structure. The 2023 method repeatedly updates the latent representation and tracks the moved point in feature maps. It is precise within StyleGAN's learned domain, but it cannot freely edit content the generator never learned.
Watch the video
If you thought generating new images was cool, or editing them with some funny filters or inpainting into them, removing objects, or adding others with correct lighting, wait until you see this amazing new research.
Called Drag Your GAN, this new paper by Pan et al. allows you to edit images directly. Here, they used a GAN, which is a known AI architecture that takes images as inputs to generate new images, often used as some kind of style transfer application.

Examples of points being dragged in images. Red are starting points, and blue are target points. Image from the DragGan paper.

The bottom row is their editing results compared to another approach (UserControllableLT) in the middle. Image from the DragGan paper.
Instead of studying how to best generate new images or to allow the user to manipulate images with text, they went to another path where the goal is to actually drag a point from A to B. So the goal is much more precise. The pixels and object starting at point A has to be at point B after the mouse dragging is done. Not only that the object will be dragged towards point B, but it will do so in a realistic manner where the goal of the GAN model is to adapt the whole image so that this part being dragged there makes sense in the resulting image.
This dragging thus manipulates the whole image, including the pose, shape, expression, and objects present in it. You can easily edit the expressions of dogs, make them sit, or do the same with humans or even edit landscapes realistically. The results are quite incredible!
This is an innovative and super cool task that I haven’t seen before. I really like this dragging interaction for image editing over trying to write what you want as clearly as possible. Am I alone on that?
Would you also prefer to edit with your hands, dragging and moving things around rather than through text inputs?
To me, this simple UI example seems really interesting and fun to play with! Anyways, what’s even cooler than the results we’ve been seeing is how DragGAN works.
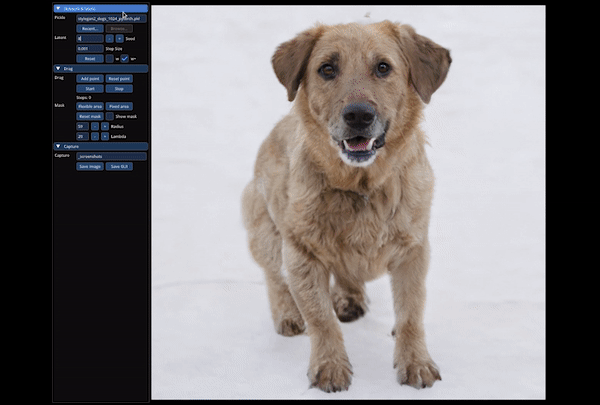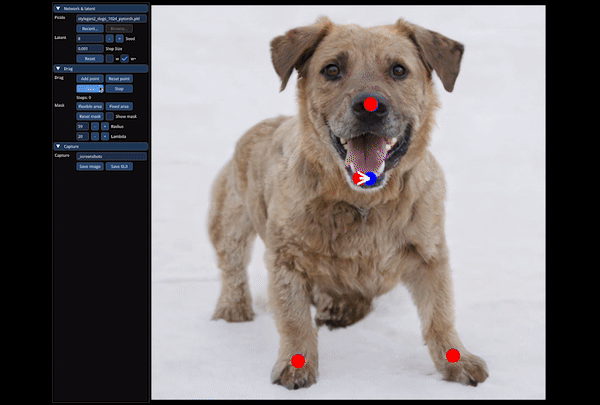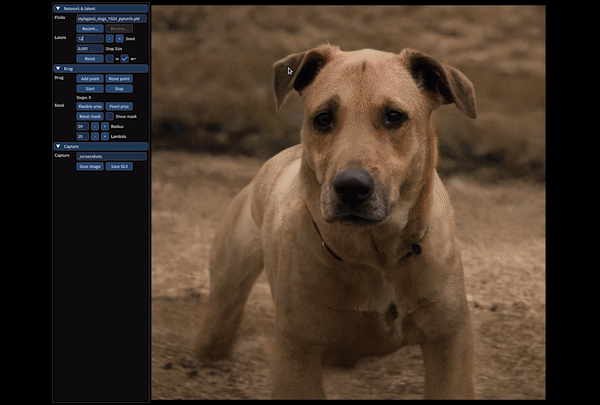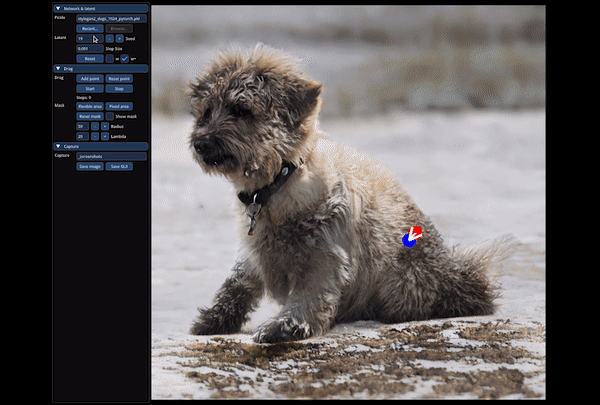
Examples of points being dragged in images. Red are starting points, and blue are target points. Image from the DragGan paper.
So to start, I will need you to have somewhat of a basic understanding of GANs. This kind of architecture is a way to train a generative model where you will train a model, called your generator, to create new images following a specific dataset. So basically imitating the images that you already have. Then, you will use another model called a discriminator to measure the quality of the generated images. During training, both models will improve together, and you will ideally end up with a powerful generative model able to replicate your true images. You can learn more about GANs in my previous articles. In this case, they use the StyleGAN2, which I covered on the channel and is a state-of-the-art GAN architecture.
Here, we have to note that any image generated from a GAN starts in the feature space. We also call this the latent code. This is a space that will basically represent the pool of images you can generate. So if you select a precise point in this space, it will have attached values to it, and by feeding those values to your generator, you will get an image. Then, if you play a bit around that space, you will generate similar images. This space is linked with the image space you can generate. Close things in there represent similar images.
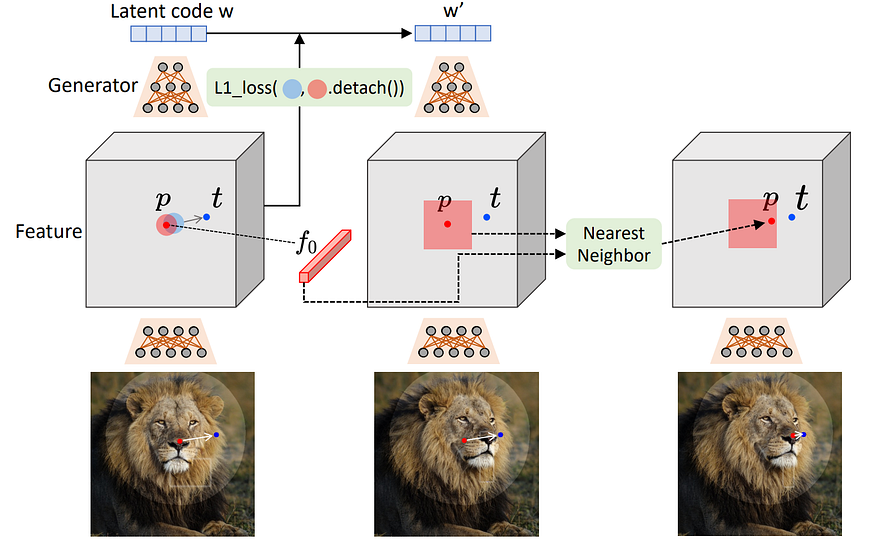
Image representing the feature maps, latent code, and image interactions. Image from the DragGan paper.
So they have two steps that they repeat until the image is at the final destination. For each new target point, the model’s first step is to take the current image and move its representation in the feature space, or latent code, towards the right point, giving us a new latent code, which we can use to generate a second image. Here we should see a slight movement in the image. Then, we adapt the new point to the actual position on the image automatically since the movement from the latent space to the real image isn’t perfect, and this is what we are aiming for with the future steps. So here, for example, the model will reposition the previous target point onto the nose of the lion for the following step, becoming the starting point. And we do that again, step by step, until we reach the final position of the point.
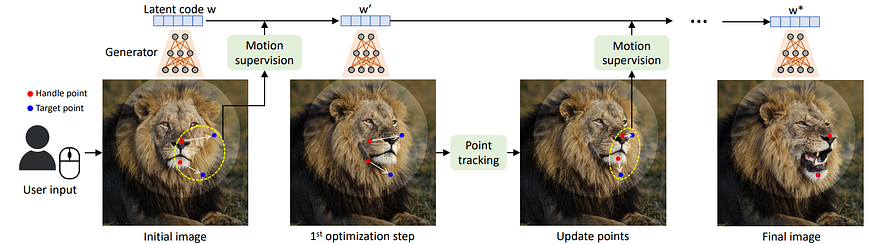
The different steps of the approach. Image from the DragGan paper.
A simple loss is applied on the feature map space, which is the in-between image we can take while the generator is working, so right in the middle of our latent code, super encoded information, and our generated image. This will suffice to train the generator to learn how to edit the images properly. Regarding the point tracking part, they will also do that directly in the in-between feature maps, finding the most similar spot from our starting point. You can see this feature map as some kind of image that would be a low resolution but still accurately represent what we have in our image both locally and globally.
Image representing the feature maps, latent code, and image interactions. Image from the DragGan paper.
There are some limitations, like only being able to edit GAN-generated images since they work in the feature space itself, or at least the controlled data has to be within the training data in order to maximize the results and not create weird artifacts. The selection of points is also important since it will be based on pixel colors and contrasts with its environment. If it is similar to all others around, it may not track well as they all look the same.

Failure cases (limitations). Image from the DragGan paper.
Still, the results are amazing, and I am super excited to see where this new sub-field of image manipulation progresses.
Of course, this was just an overview of this great new paper, and I definitely invite you to read it for more information on how it works and see more results. The authors mention that the code should be available in June, so if you read the article before that, well, be patient just a little, and hopefully, we will be able to play with this approach soon!
References
►More results and upcoming code: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
►Pan et al., DragGAN, https://arxiv.org/abs/2305.10973
►Twitter: https://twitter.com/Whats_AI
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
►Support me on Patreon: https://www.patreon.com/whatsai
►Join Our AI Discord: https://discord.gg/learnaitogether
FAQ
What does DragGAN let a user do?
It lets a user drag a selected image point toward a target while the generator updates the scene realistically.
Why not move the pixels directly?
A raw pixel shift creates artifacts, while the generator can adapt shape, texture, pose, and surrounding context.
What is a handle point?
It is the point on the generated object that the user selects and asks the model to move.
Why optimize inside the feature-map space?
Intermediate features preserve local and global structure better than treating the final image as unrelated pixels.
Does DragGAN edit any arbitrary photograph?
It works through a trained GAN's representation, so edits remain constrained by what that generator can represent.