

The short version
A GAN creates images by training a generator and discriminator against each other. The generator produces candidates from learned representations, while the discriminator tries to separate generated images from real training examples; repeated feedback improves the output. This 2021 explainer covers one important image-generation family, not every method used today, and the learned results remain limited by the training data.
- Image generation models learn patterns from training data, then combine those patterns into new images guided by prompts or conditions.
- The impressive part is not only the final image, but the representation the model learned about objects, styles, and composition.
- Generated images still need checks for artifacts, bias, copyright questions, identity issues, and whether the output matches the intended use.
Watch the video and support me on YouTube
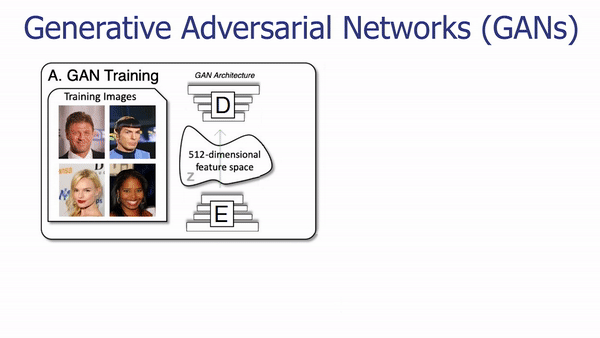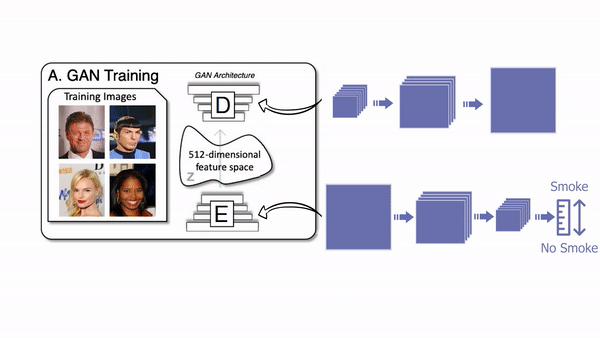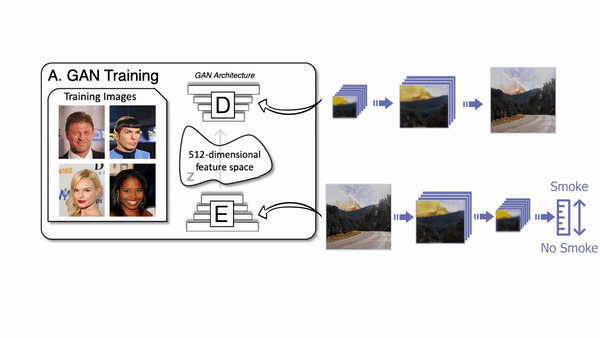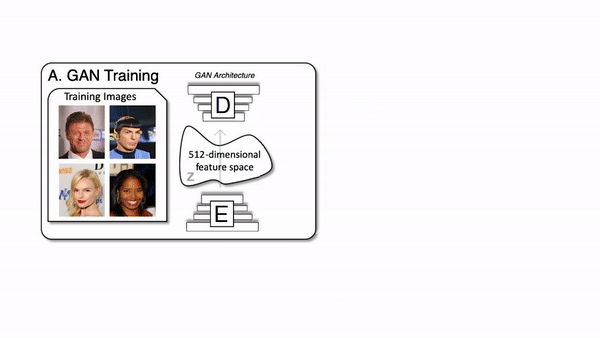
The architecture of the generator of a GAN network.
To generate new images, we use an architecture called Generative Adversarial Networks. It works with a generator composed of an encoder and a decoder and a discriminator. For the generator, both the encoder and decoder are convolutional neural networks, but the decoder works in reverse. Here’s how it works: The encoder receives an image, encodes it into a condensed representation. The decoder takes this representation to create a new image changing the image Style.
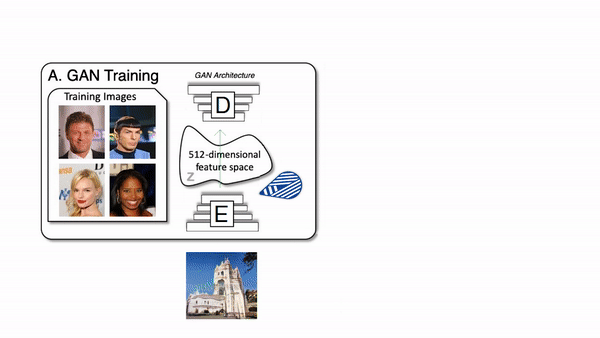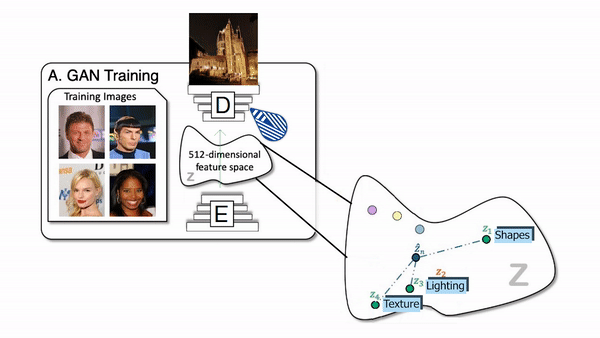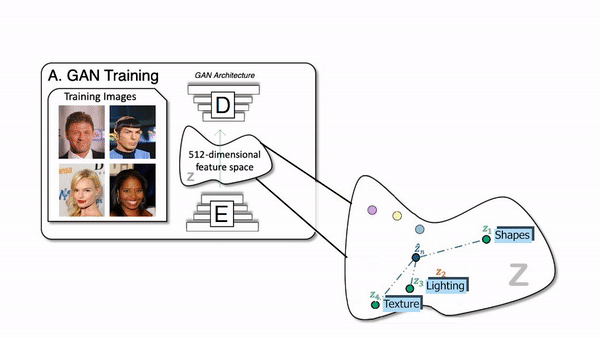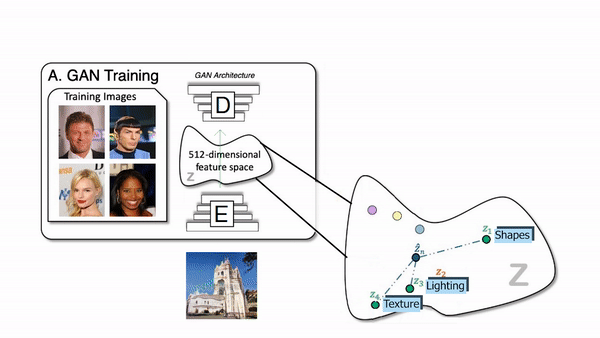
How the generator of a GAN network works.
This is repeated numerous times with all the images we have in our training data set so that the encoder and decoder learn how to maximize the results of the task we want to achieve during training.
A classic GAN architecture will have a generator trained to generate the image and a discriminator used to measure the quality of the generated images by guessing if it’s a real image coming from the data set or a fake image generated by the generator. Both networks are typically composed of convolutional neural networks, which I covered in a previous article. As we already discussed, the generator looks like this (see below), mainly composed of downsampling the image using convolutions to encode it. Then it upsamples the image again using convolutions to generate a new version of the image with the same style based on the encoding. Its goal is to generate realistic images.
The generator creating fake images.
Then the discriminator takes the generated image, or an image from your data set and tries to figure out whether it is real or generated, called fake. This is repeated numerous times with all the images we have in our training data set. It also uses a convolutional neural network, but only the encoding part as it tries to take an image and understand it.

The discriminator trying to tell if the image it receives is real or fake.
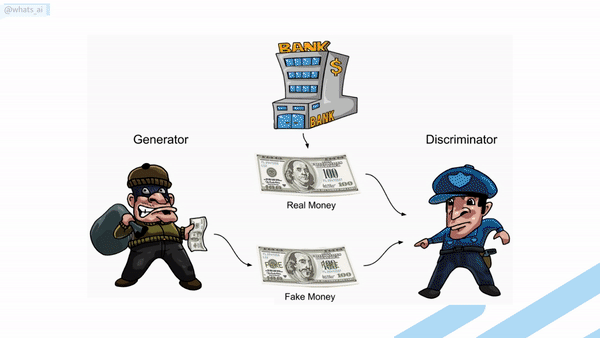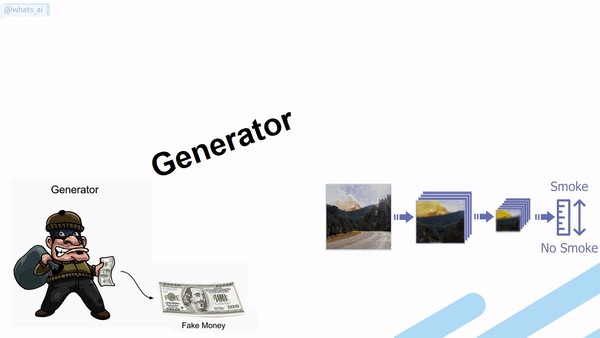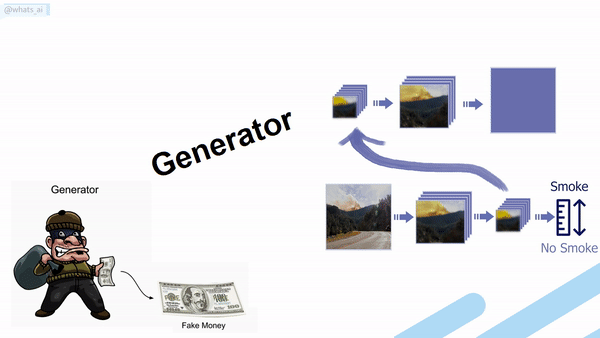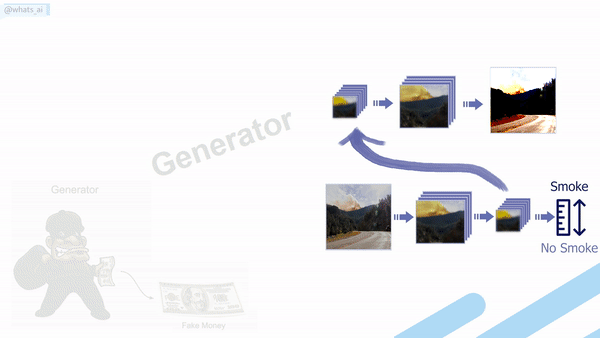
GANs are a clever way of training a generative model (the generator) by framing the problem as a problem with two sub-models: the generator model that we train to generate new examples and the discriminator model that tries to classify examples as either real (from the domain) or fake (generated). The two models are trained together in a zero-sum game, adversarial, until the discriminator model is fooled about half the time, meaning the generator model generates plausible examples. In this case, zero-sum means that when the discriminator successfully identifies real and fake samples, no change is needed to the model parameters, but the generator is penalized with large updates to model parameters (in the case of a fake image being identified as fake since the generator failed its task). Alternately, when the generator fools the discriminator, no change is needed to the model parameters, but the discriminator is penalized, and its model parameters are updated. The important thing is that only one of the two networks is penalized at each step. This way, the two models are improved together, and the generator generates more realistic images over time.
As illustrated above, we can think of the generator as being like a counterfeiter, trying to make fake money, and the discriminator as being like police, trying to allow legitimate money and catch counterfeit money. To succeed in this game, the counterfeiter must learn to make money indistinguishable from genuine money. Thus, the generator network must learn to create samples from the same distribution as the training data, so they look alike and fool the police with fake money.
Once the training is done, you can send an image to the encoder, and it will do the same process, generating a new and unseen image following your needs. It will work very Similarly, whatever the task, whether it’s to translate an image of a face into another style, like a cartoonifier, or create a beautiful landscape out of a quick draft.
Thank you for reading,
— Louis
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
FAQ
How does AI generate new images?
AI image models learn visual patterns from many images, then generate new pixels or latent representations that match a prompt, class, or condition.
Does AI copy images from the training set?
Most systems generate new outputs from learned patterns, but memorization and style imitation can still happen, which is why data and licensing matter.
Why do prompts change generated images?
Prompts condition the model, giving it language constraints that steer the scene, style, objects, composition, and details it tries to create.
What should you inspect in AI-generated images?
Inspect fine details, text, hands, faces, consistency, bias, artifacts, and whether the image could mislead someone about what really happened.
How should beginners understand image generation?
Start with the idea of learned visual representations, then study GANs, diffusion models, conditioning, latent spaces, and evaluation.