AI Image Editing from Text! Imagic Explained
Imagic: Manipulate images using pre-trained image generator models!


Watch the video
This week’s paper may just be your next favorite model to date.
If you think the recent image generation models like DALLE or Stable Diffusion are cool, you just won’t believe how incredible this one is.
This is Imagic:

Imagic takes such a diffusion-based model able to take text and generate images out of it and adapts the model to edit the images. Just look at that... You can take an image and teach the model to edit it any way you want.
This is a pretty big step towards having your very own photoshop designer for free.
The model not only understands what you want to show, but it’s also able to stay realistic as well as keeping the properties of the initial images. Just look at how the dog and person stay the same in all images here.

This task is called text-conditioned image editing. This means editing images by only using text and an initial image, which was pretty much impossible not even a year ago. Now, look at what it can do!
Yes, this is all done from a single input image and a short sentence where you say what you’d like to have. How amazing is that?!
The only thing even cooler is how it works. Let’s dive into it!
But first, if you are currently learning AI or want to start learning it you will love this opportunity.
I know how hard it can be to make real progress when learning AI. Sometimes extra structure and accountability can be what propels you to the next level.
If that sounds like you, join my friend sponsoring this content at Delta Academy. At Delta Academy, you learn Reinforcement Learning by building game AIs in a live cohort. Go from zero-to-AlphaGo through expert-crafted interactive tutorials, live discussions with the experts, and weekly AI-building competitions.
It's not just another course spam website: it's intense, hands-on, and focused on high quality, designed by experts from DeepMind, Oxford, and Cambridge. It's where coders go to future-proof their career from the advance of AI and have fun.
Plus with a live community of peers and experts to push you forward, you'll write iconic algorithms in Python, ranging from DQN to AlphaGo, one of the coolest programs ever made.
Join them now through my link and use the promo code WHATSAI to get 10% off!

So how does Imagic work?

As we said, it takes an image and a caption to edit the said image. And you can even generate multiple variations of it!
This model, like the vast majority of the papers that are released these days, is based on diffusion models. More specifically, it takes an image generator model that was already trained to generate images from text and adapts it to image editing. In their case, it uses Imagen, which I covered in a previous video. It is a diffusion-based generative model able to create high-definition images after being trained on a huge dataset of image-caption pairs.
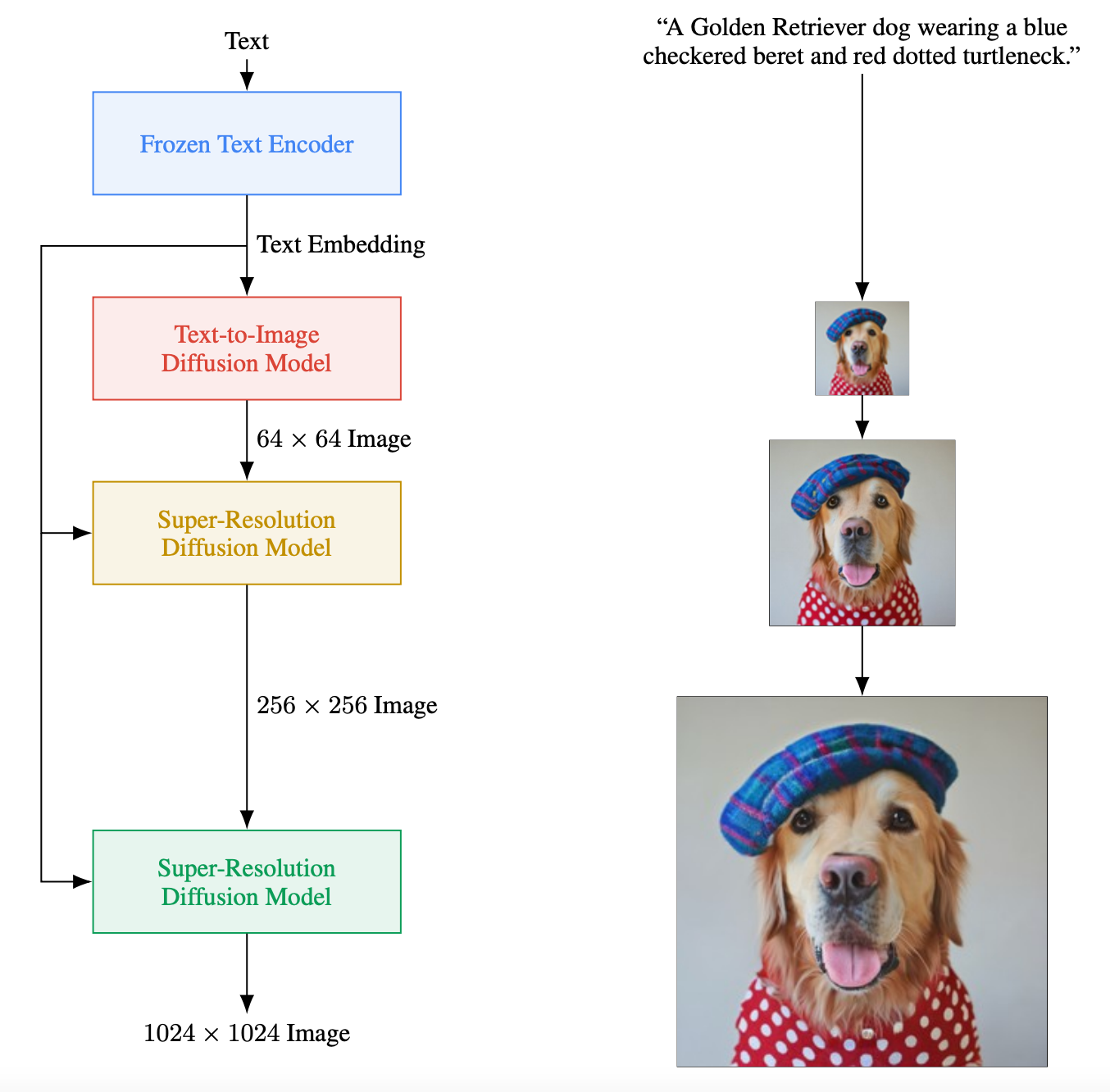
In the case of Imagic, they simply take this pre-trained Imagen model as a baseline and make modifications to it in order to edit the image sent as input, keeping the image-specific appearance, such as the dog’s race and identity, and editing it following our text.
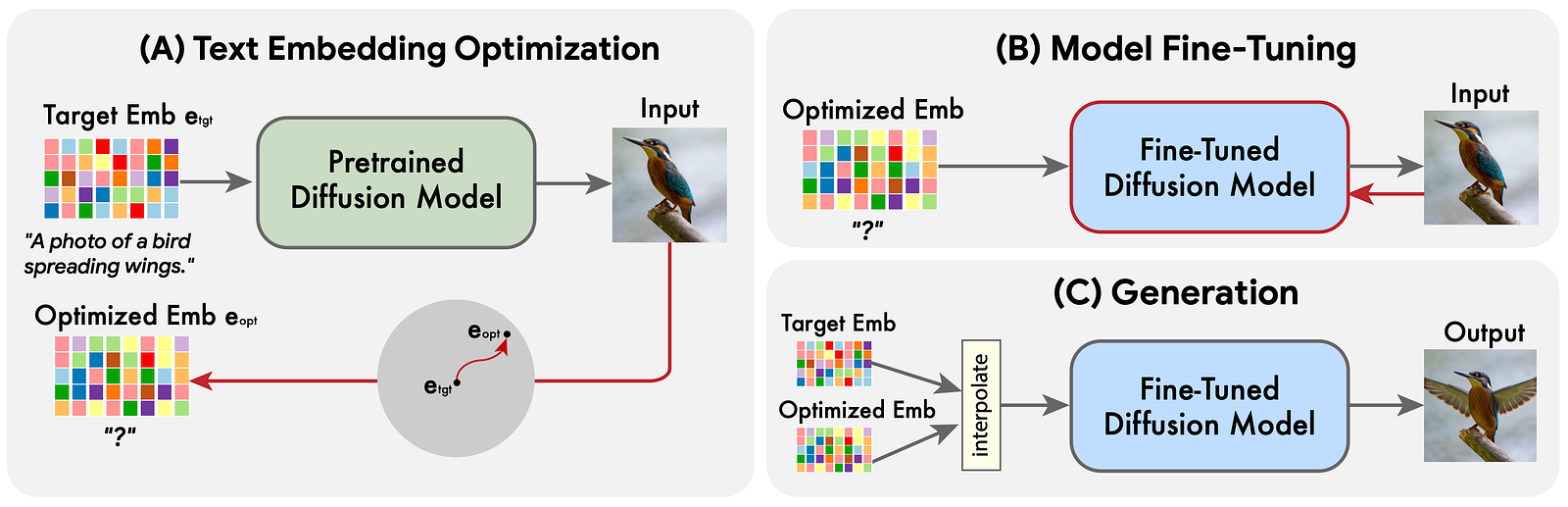
So to start (image above, left), we have to encode both the text and the initial image so that it can be understood by our Imagen model. When this is done, we optimize our encodings, or text embeddings, to better fit our initial image. Basically, taking our text representation and optimize it for our initial image, called e_opt, to be sure it understands that, in this example, we want to generate the same kind of image with a similar-looking bird and background.
Then, we take our pre-trained image generator to fine-tune it. Meaning that we will re-train the Imagen model keeping the optimized embedding we just produced the same. So these two steps are used to get the text embedding closer to the image embedding by freezing one of the two and getting the other closer, which will ensure that we optimize for both (a and b, image above) the text and initial image, not only one of the two.
Now that our model understands the initial image and our text and understands that they are similar, we need to teach it to generate new image variations for this text.
This part is super simple. Our text embeddings and image-optimized embeddings are very similar but still not the exact same. The only thing we do here is that we take the image embedding in our encoded space and move it a bit toward the text embedding.
At this moment, if you ask the Imagic model to generate an image using the optimized embeddings, it should give you the same image as your input image. So if you move the embedding a bit toward your text’s embeddings, it will also edit the image a bit toward what you want (image above, c). The more you move it in this space, the more the edit will be big and the farther away you will get from your initial image. So the only thing you need to figure out now is the size of the step you want to take toward your text.
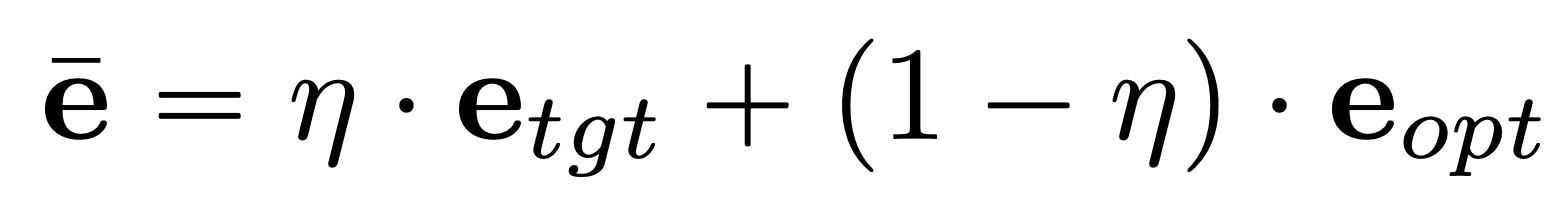
And voilà!
When you find your perfect balance, you have a new model able to generate as many variations as you want to conserve the important image attributes while editing the way you want!
Of course, the results are not perfect yet, as you can see here, where the model either does not edit properly or does random image modifications to the initial image, like cropping or zooming inappropriately. Still, it stays pretty impressive if you ask me. I find the pace of the image generation progress incredible, and that’s both amazing and scary at the same time. I’d love to know your opinion on these kinds of image-generating and image-editing models. Do you think they are a good or bad thing? What kinds of consequences you can think of from such models becoming more and more powerful?

You can find more details on the specific parameters they used to achieve these results in their paper, which I definitely invite you to read.
I also invite you to read my article covering Imagen if you’d like more information about the image generation part and how it works.
I will see you next week with another amazing paper!
References
►Kawar, B., Zada, S., Lang, O., Tov, O., Chang, H., Dekel, T., Mosseri, I. and Irani, M., 2022. Imagic: Text-Based Real Image Editing with Diffusion Models. arXiv preprint arXiv:2210.09276.
► Use it with Stable Diffusion: https://github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/