Generate music with AI: Stable Audio Explained
New AI That Generates Amazing Music !


Watch the video:
Did you know AI can already create amazing music?
Yep, that’s right. Not only can we do that in a research context, coding it yourself, but on a website where you can just enter a quick text description of what you want and get a music sample! And the best thing is you can try it for free for up to 20 tries a month! Indeed, the same team behind Stable Diffusion just released Stable Audio. Stable Audio, by Stability AI, works in a very similar way as stable diffusion, able to understand the text and transform those abstract words into a musical representation, just like stable diffusion does for images. And even better than it being free: they openly shared how they achieved that, so let’s dive into it!
As you’ve seen many times on my channel, most new generative approaches, especially involving images and other complex signals, are based on an approach we call diffusion networks, like, well, stable diffusion, for example.
Why is this important? And why do I bring up stable diffusion again? Well, for two reasons. First is that diffusion models are powerful networks that take noise and can generate outputs from it. They do that by learning to add noise repeatedly until it converges back to a real image. This is possible because we train the model in reverse, starting with images and corrupting the image little by little while also letting the model know how we corrupt it. Over millions of trials and examples, our model learns the noise patterns and is able to take full noise and construct an input, like an image.

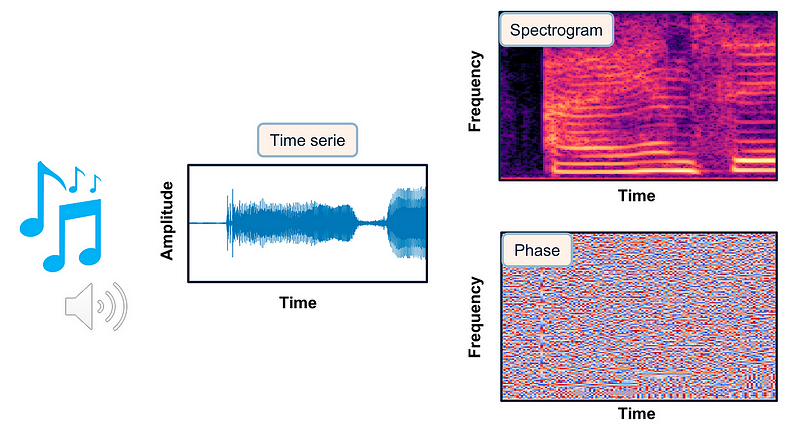
But here we are talking about sound, so why is this relevant? In fact, sound is pretty similar to images. A sound can be converted in a magnitude spectrogram. It’s a visual representation of all the frequency content of the sound over time, with the x-axis showing time and the y-axis showing frequency. Here, the color also indicates the amplitude of each frequency component.
Then, when we have it in a similar shape as an image, we can use a very similar network to encode this sound into a new representation, which is basically the most important feature of the sound extracted from the original input. A network we call the encoder is trained to do that, thanks to hundreds of thousands of examples. Now, we do the same thing as with the image model, taking our initial audio sample and adding noise to it. Thanks to this latent information at hand, we can leverage it to feed information about our initial audio sample and teach our model to reconstruct the same sound we fed, which was lost because of the added noise. And now, we have a model able to reconstruct a sound. Why is that useful?
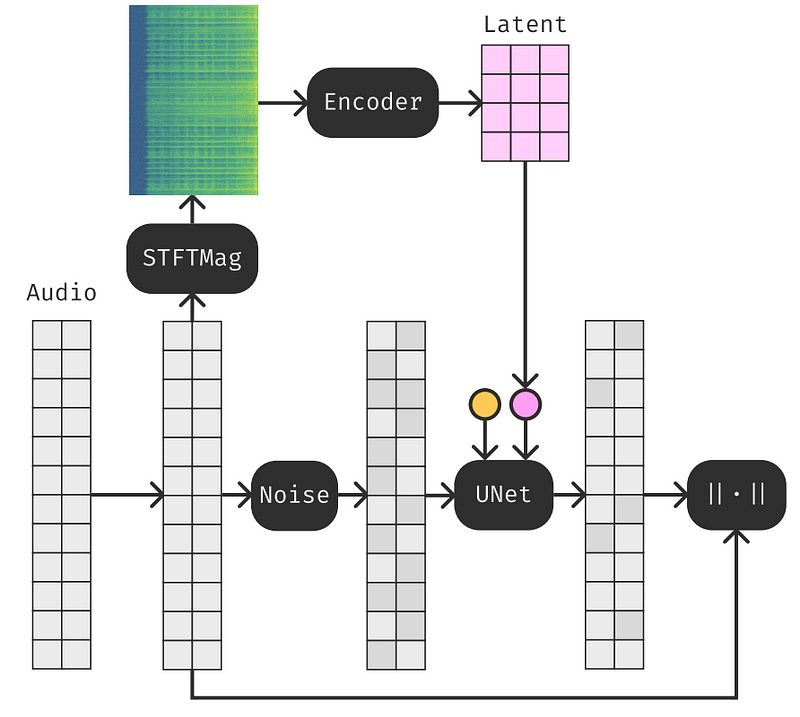
Because this model is the most essential part of the problem, it allows us to give information; in this case, it was the latent information of the initial audio and reconstruct the sound.
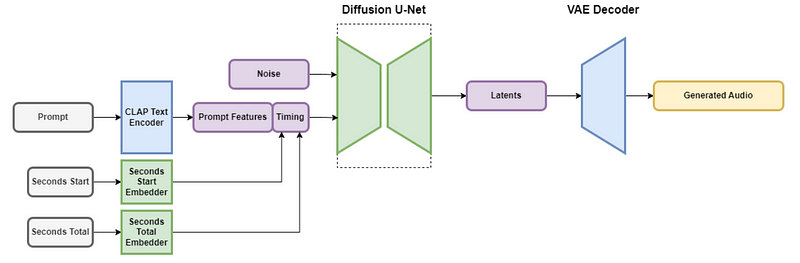
What is cool is that we can transform pretty much any sort of information into a similar latent representation using different networks trained for that. In this case, it is the CLAP Text encoder that they train to transform the text input into a good representation for our generative model.
Here, they also have a VAE Decoder. This is simply because, as with the latent diffusion model, they work in a compressed representation of sounds for training and inference efficiency. You can see that as a blurry image or the song you hear from the guy with the loud cell phone in the back of the bus. It contains all the information, but it just sounds bad. So they have a last model that has only the focus of making it sound good. Just like upscaling images, here you upscale sound.
And voilà! You have your new model that is trained to generate a song that represents text, which was transformed into a latent representation, basically a compressed form with only the most valuable information, and given to our generator network, unblurring our song-image into a new song!

But. A song isn’t like an image. It isn’t fixed in space. A song isn’t a square; it has a duration, and that duration varies. How can we deal with variable output length and generate any song we want? Well, we simply give the model more information! During training, we have access to all the data, so we can give it the text to generate the song, obviously, but we can also give it more information since the song it needs to create already exists. They decided to feed it the parts of songs with their start time and total length. This is used to allow the model to understand how long the song generated should be and understand various lengths as well as what to generate next. It distinguishes if it has to create a nice riff, a song ending, etc.
And voilà! With this model called Stable Audio, based on the Moûsai text-to-music generation model, similar to stable diffusion but with sound and the CLAP encoder for our text, you can quickly generate any song you want following your text!
By the way, if you were wondering what the results sound like, you can listen to them throughout my entire video! All music used in this video was generated using stable audio, so zero humans were involved here, and purely AI produced them! How cool is that?! You can also try it on their platform or just listen to the results shared on their blog post. All links are in the description below!
Let me know what you think of the article and the stable audio results. I will see you next time with more exciting new AI research! Also, share your creations with us on Discord!
Reference
►Read the full article: https://www.louisbouchard.ai/stableaudio/
►Stableaudio: https://stableaudio.com/
►Research blog post: https://stability.ai/research/stable-audio-efficient-timing-latent-diffusion
►Twitter: https://twitter.com/Whats_AI
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/
►Support me on Patreon: https://www.patreon.com/whatsai
►Join Our AI Discord: https://discord.gg/learnaitogether