StyleGANEX: Enhancing Image Manipulation with Dilated Convolutions
Enhance Your Photos with AI: From HD Upscaling to Cartoon Filters


Watch the video
Let’s talk about the Ai models that take your face and can transform it into a funny cartoon, edit facial attributes like changing your hair color, or simply upscale your image to make it more HD. If you’ve been following my articles, you know that most of these applications rely on a single model and its multiple versions called StyleGAN, which I covered numerous times already. StyleGAN is a GAN-based architecture developed by NVIDIA that can take an input and transform it into another one following a specific given style it was trained on. It’s also open source meaning that everyone can use and build on it, and why all the research papers are using it.

The problem with StyleGAN is that it is limited to cropped and aligned faces at a fixed image resolution from the data it was trained on. Meaning that for images of the real world, you need other approaches to find the face, crop it out, and re-orient it, and it also must have the same image resolution. This is a big problem since you usually want to have high-quality images but training with them would be incredibly long.
So what we typically do is we use the StyleGAN architecture to make the style transfer of our image, and then we use another network to upscale the image to a higher resolution. While this approach works well, it’s definitely not ideal. You need two models instead of one, adding more biases and potential errors, as well as needing to train both and limiting the generalizability capabilities. Fortunately for us, some amazing researchers are working on this limited input image problem and have recently published a new approach at ICCV 2023 called StyleGANEX through some very clever small changes. Plus, the code, pre-trained models, and a demo online are all available to try it yourself. All the links are in the references below.
Obviously, the architecture is mostly based on StyleGAN, which has lots of pre-trained models you can play with, but all have this input image size issue we discussed, which ends up producing different encodings in the latent space, too, since they all follow the same convolutions. So everything is of different sizes based on the image you want to process. Here, the researchers did a simple fix to this issue by implementing a dilated convolution to rescale the receptive fields of shallow layers in the StyleGAN generator architecture. But what does this mean?
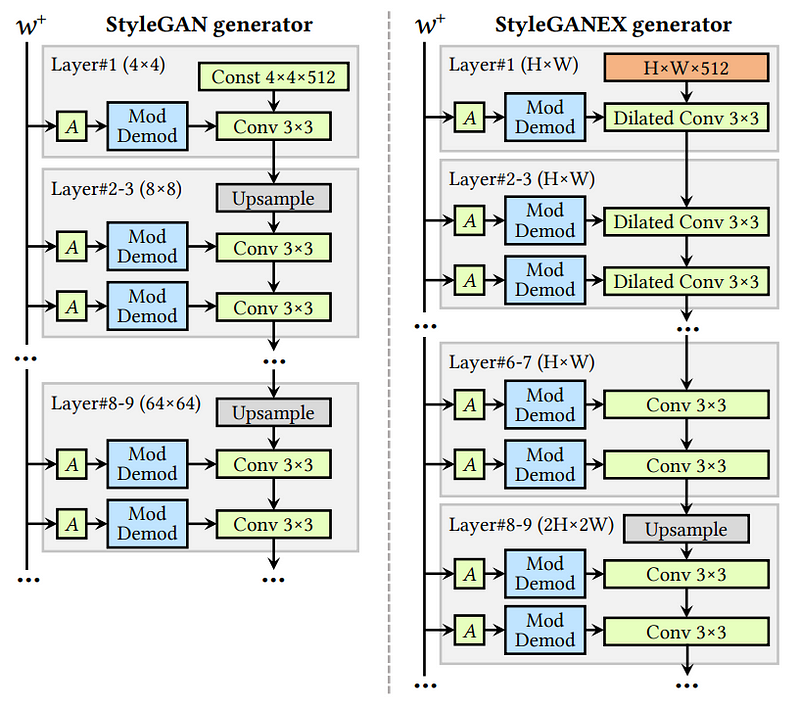
In simple terms, it means the new filters in the early layers of the generator model can get larger depending on the image input size, regardless if it was trained with this size or not. Making the generator model able to accommodate many different resolutions dynamically. It can also do that without the need for retraining, meaning that you can actually use your current StyleGAN pre-trained model and just use their new decoder to allow for flexible input sizes, both in the image and in the latent space.
So, yes, what they changed are these single initial convolution blocks to replace with dilated convolutions, and voilà, you can generate images from the encoding of any image size now and manipulate them in the latent space to then generate your stylized version!
But what are those dilated convolutions exactly, and why can they adapt to any image and have similar performances? Plus, how does it work without having to be re-trained from a regular StyleGAN model?!

The idea of the dilated convolution is to have the output be of the same size regardless of the input size, or here our latent space information size since we have our information processed and are aiming to use it to reconstruct a stylized image. This means the convolution filters that go through the latent space information to process it and generate our stylized image will change size depending on the input size to end up with the same number of output pixels for any incoming information. Then, you can easily work with all your images. As you see in the figure above, the latent code of StyleGANEX is of variable size compared to the fixed 4x4 from StyleGAN, which was produced by processing cropped and re-scaled images. The flexible dilated convolution with variable filter size allows for the resolution of the first feature map, or processed image, to be 32 times smaller than the original image at all times, instead of fixed 4x4, thus maximizing information for larger images too.
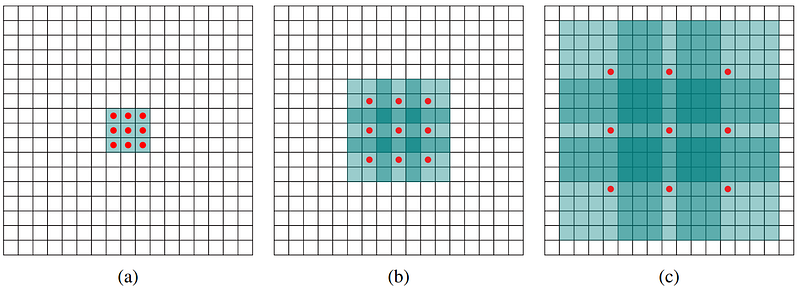
In regular convolutions, a small filter (like 4x4 here) slides over the input image, and at each location, the element-wise product between the filter and the local input region is computed. This process is repeated for each position in the input image to generate the output feature map.
Dilated convolutions introduce the concept of “dilation rate”. Instead of placing the convolutional filter elements densely, one pixel over the other, the filter elements are spaced apart with gaps. This effectively expands the receptive field of the convolution operation without increasing the size of the filter. This means that increasing the dilation rate for a larger image will make it so your filter sees the same ratio of the image. The dilation rate determines the spacing between the elements of the filter. So you basically expand your filters by the dilation rate, which would be 1 since all elements are adjacent for a regular convolution, filling all holes with zeros in between each original parameter. So a dilation of two would mean your filter is twice the size of the original one. Then you can fill the rest of the values with either zeros, à priori knowledge from your data distributions, or learn it during training.
If you fill the holes in the filters with zeros you then don’t require any further training. You only need to figure out the dilation rate based on the input size and that’s it, which is why they can take any StyleGAN generator and adapt it automatically.
That was for the generator part, so the right part of the overall model, shown here, that takes the latent code and generates your final image.
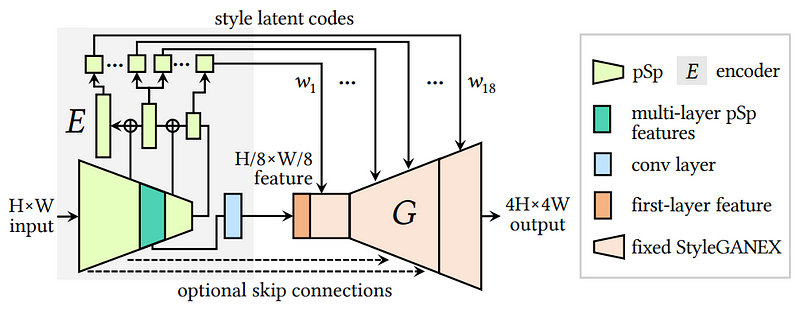
If you want to also process images and not only generate random ones, you need a dynamic generator as well that will be able to understand any image size and save this understanding into latent codes. Here they used pSp, or pixel2style2pixel, a widely used encoder architecture. It encodes an image into a latent space based on the input image size, and then they use pooling to condense the features into the latent codes that will be used in the decoders so they aren’t too large.

And voilà! Using the dilated convolutions in the generator and this encoder, you can perform face manipulations with any image size without retraining!
Of course, this was just an overview of this new StyleGANEX paper that I strongly recommend reading for a deeper understanding of the approach. I also did not cover the whole StyleGAN architecture but you can find many articles about it on on my blog if you are interested! This is also the first of a few articles I will do covering ICCV 2023 papers, so you should definitely follow the blog and newsletter if you enjoyed it. As I said at the beginning of the article, you can try it yourself either via their demo online or by implementing their code and available pre-trained models. If you do try it, please let me know your thoughts on the quality of the image manipulation! I hope you’ve enjoyed this article, and I will see you next time with another amazing paper!
References
►Read the full article: https://www.louisbouchard.ai/styleganex/
►Demo: https://huggingface.co/spaces/PKUWilliamYang/StyleGANEX
►Paper: https://arxiv.org/abs/2303.06146
►Code: https://github.com/williamyang1991/StyleGANEX
►Project page: https://www.mmlab-ntu.com/project/styleganex/
►Twitter: https://twitter.com/Whats_AI
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/
►Support me on Patreon: https://www.patreon.com/whatsai
►Join Our AI Discord: https://discord.gg/learnaitogether