
The short version
DeepETA was Uber’s 2022 deep-learning system for adjusting estimated arrival times from route and live trip features. The pipeline discretized numerical inputs, used embeddings and a transformer-like linear-attention model, then corrected the road-network estimate while targeting low latency across rides and deliveries. Read it as a description of Uber’s system then, not a claim about the company’s current production architecture.
- Uber's ETA problem is a good example of AI working inside a real product where small errors matter to millions of users.
- The model has to combine maps, traffic, routes, demand, historical behavior, and live signals instead of relying on one simple feature.
- Production ML is not only training. It is monitoring, feedback, latency, data pipelines, and constant evaluation against real outcomes.
Watch the video
How can Uber deliver food and always arrive on time or a few minutes before? How do they match riders to drivers so that you can *always* find a Uber? All that while also managing all the drivers.
We will answer these questions in this article with their arrival time prediction algorithm: DeepETA. DeepETA is Uber’s most advanced algorithm for estimating arrival times using deep learning. Used both for Uber and Uber Eats, DeepETA can magically organize everything in the background so that riders, drivers, and food are fluently going from point a to point b in time as efficiently as possible.
Many different algorithms exist to estimate travel on such road networks, but I don’t think any are as optimized as Uber’s. Previous arrival time prediction tools, including Uber, were built with what we call shortest-path algorithms, which are not well suited for real-world predictions since they do not consider real-time signals.
For several years Uber used XGBoost, a well-known gradient-boosted decision tree machine learning library. XGBoost is extremely powerful and used in many applications but was limited in Uber’s case as the more it grew, the more latency it had. They wanted something faster, more accurate, and more general to be used for drivers, riders, and food delivery. All orthogonal challenges that are complex to solve, even for machine learning or AI.
Here comes DeepETA. A deep learning model that improved upon XGBoost for all of those.
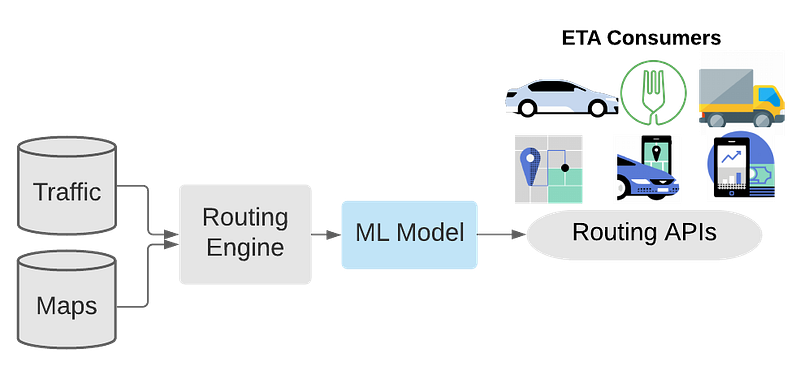
Hybrid approach of ETA post-processing using ML models. Image from Uber’s blog.
DeepETA is really powerful and efficient because it doesn’t simply take data and generate a prediction. There’s a whole pre-processing system to make this data more digestible for the model. This makes it much easier for the model as it can directly focus on optimized data with much less noise and far smaller inputs, a first step in optimizing for latency issues.
This pre-processing module starts by taking map data and real-time traffic measurements to produce an initial estimated time of arrival for any new customer request.
Then, the model takes in these transformed features with the spatial origin and destination and time of the request as a temporal feature. But it doesn’t stop here. It also takes more information about real-time activities like traffic, weather, or even the nature of the request, like delivery or a rideshare pickup.
All this extra information is necessary to improve from the shortest-path algorithms we mentioned that are highly efficient but far from intelligent or real-world proof.
And what does this model use as an architecture?
You guessed it: a transformer! Are you surprised? I’m definitely not.
And this directly answers the first challenge, which was to make the model more accurate than XGBoost. I’ve already covered transformers numerous times on my channel, so I won’t go into how it works in this article, but I still wanted to highlight a few specific features for this one. First, you must be thinking “but transformers are huge and slow models; how can it be of lower latency than XGBoost?!”
Well, you would be right. They’ve tried it, and it was too slow, so they made some changes.
The change with the biggest impact was to instead use a linear transformer, which scales with the dimension of the input instead of the input’s length. This means that if the input is long, transformers will be extremely slow, and this is often the case for them with as much information and routing data. Instead, it scales with dimensions, something they can control that is much smaller.
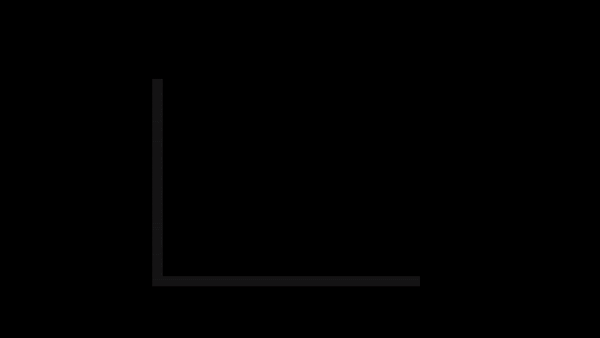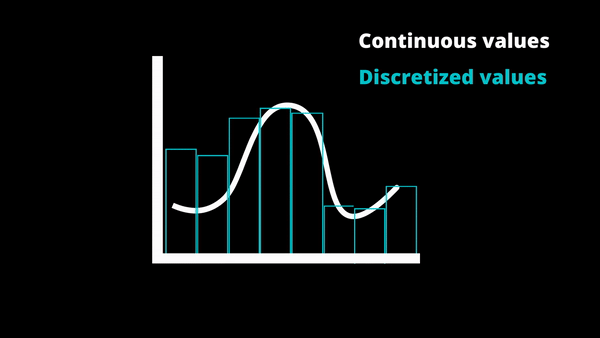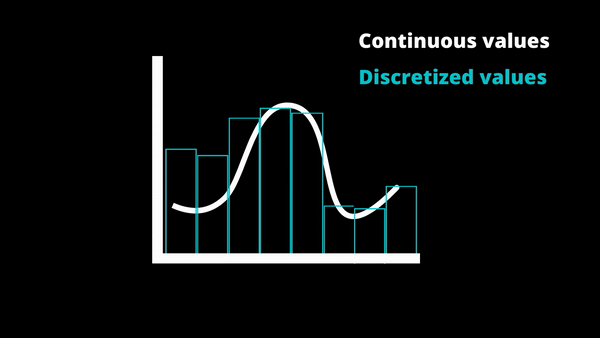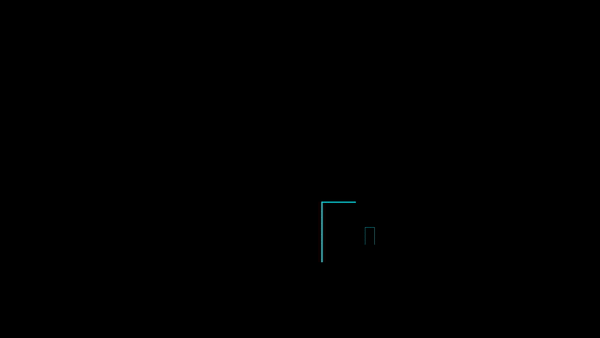
Another great improvement in speed is the discretization of inputs. Meaning that they take continuous values and make them much easier to compute by clustering similar values together. Discretization is regularly used in production to speed up computation as the speed it gives clearly outweighs the error the duplicate values may bring.
Now, there is only one challenge left to cover, and by far, the most interesting is how they made it more general.
Here is the complete DeepETA model to answer this question.
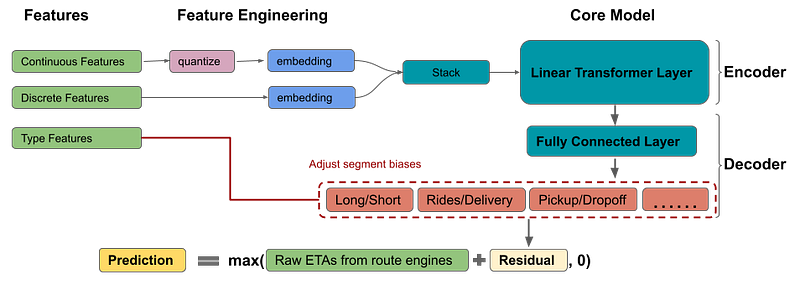
Illustration of the DeepETA model structure. Image from Uber’s blog.
There is the earlier quantization of the data that are then embedded and sent to the linear transformer we just discussed. Then, we have the fully connected layer to make our prediction, and we add a final step to make our model general: the bias adjustment decoder.
It will take the predictions and the “type features” we mentioned at the beginning of the article containing the reason the customer made a request to Uber to orient the prediction to a more appropriate value for the task. They periodically re-train and deploy their model using their own platform called Michelangelo, which I’d love to cover next if you are interested. If so, please let me know in the comments of the video or by DMs/email!
And voilà!
This is what Uber currently use in their system to deliver and give rides to everyone as efficiently as possible!
Of course, this was only an overview, and they used more techniques to improve the architecture, which you can find out in their great blog post linked below if you are curious. I also just wanted to note that this was just an overview of their arrival time prediction algorithm, and I am in no way affiliated with Uber.
I hope you enjoyed this week’s article covering a model applied to the real world instead of a new research paper, and if so, please feel free to suggest any interesting applications or tools to cover next. I’d love to read your ideas!
Thank you for reading, and I will see you next week with another amazing paper!
References:
►Read the full article: /uber-deepeta/
►Uber blog post: https://www.uber.com/us/en/blog/deepeta-how-uber-predicts-arrival-times/
►What are transformers: https://youtu.be/sMCHC7XFynM
►Linear Transformers: https://arxiv.org/pdf/2006.16236.pdf
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
FAQ
What is Uber DeepETA?
DeepETA is Uber's machine learning approach for estimating arrival times by learning from route, traffic, location, and historical trip data.
Why is ETA prediction hard?
Travel time changes with traffic, routing, weather, driver behavior, demand, city layout, events, and many small real-world signals.
Why does ETA accuracy matter?
Better ETA predictions improve user trust, pickup planning, marketplace efficiency, and the decisions riders and drivers make in the app.
What makes this a production ML problem?
The system has to run fast, update with fresh data, handle cities differently, monitor failures, and improve from real trip outcomes.
What can AI builders learn from DeepETA?
Start from the product decision, use the data available at prediction time, and measure whether the model improves the user experience.